(译)SRP Batcher Speed up your rendering!
推荐去个人网站或者原文观阅文章,因为文章中有嵌入式视频:
https://www.lfzxb.top/srp-batcher-speed-up-your-rendering/
本文翻译自:SRP Batcher: Speed up your rendering! 和 https://docs.unity3d.com/Manual/SRPBatcher.html
在2018,我们介绍了一个被称为SRP的高度自定义的渲染技术,一个被称为SRP Batcher新的引擎底层Loop就是这个技术的一部分,SRP Batcher可以在渲染时加速你的CPU 1.2到4倍(这取决于你的场景)。让我们看看如何这个功能的最佳实践吧!
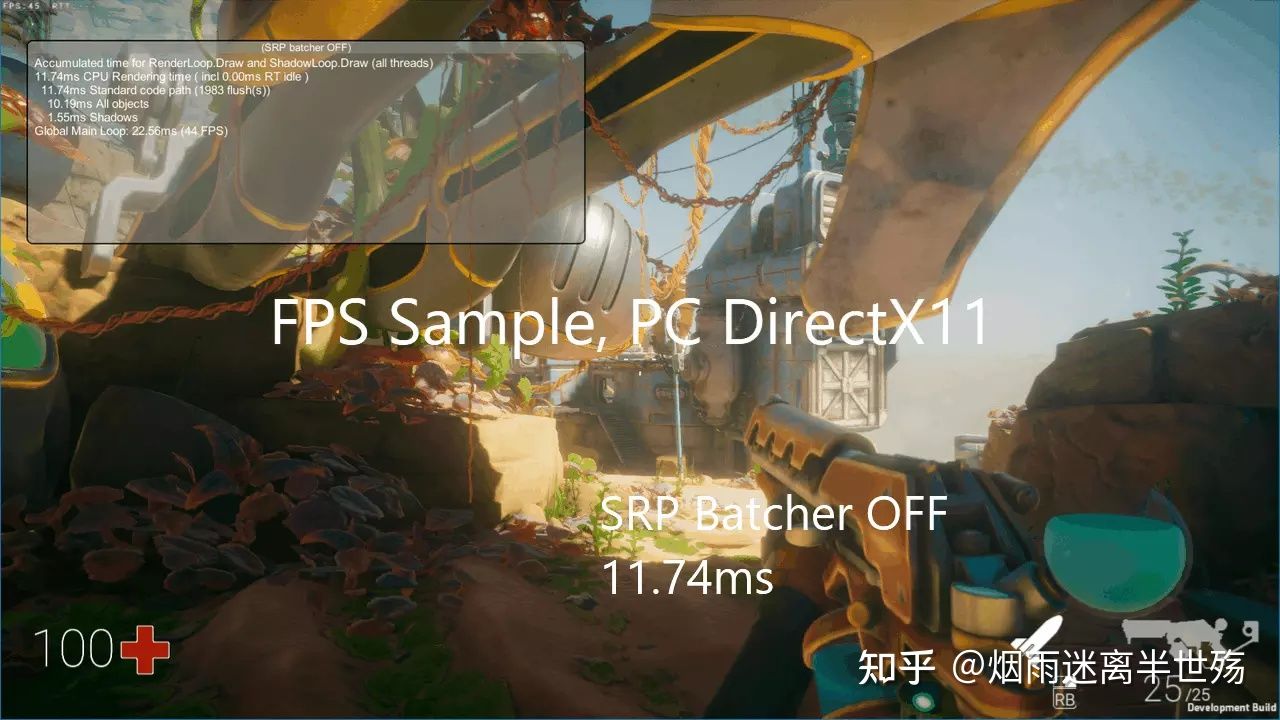
上面那个视频显示了Unity渲染时最坏的一个场景:每个对象都是动态的,并且使用不同的材质(材质的颜色或者贴图等属性不同),所以尽管非常多相同的Mesh,但是在渲染时每个Mesh都会被当成不同的Mesh进行渲染(所以无法使用GPU Instance优化技术)。这个场景使用SRP Batcher在PS4平台上可以加速4倍(这个视频是PC的,渲染API是DX11)
注意:当我们谈及4倍的加速时,我们说的是CPU端的渲染相关代码(例如在Profiler中显示的“RenderLoop.Draw”h和“ShadowLoop.Draw”标签),而不是总的渲染帧率。
Unity和Materials
Unity是一个非常灵活的渲染引擎,你可以在一帧的的任何时间点修改任何Material属性。此外,Unity历史版本的渲染管线并不是面向Constant Buffer进行开发的,这是为了支持DX9这样的图形API。但是,这样漂亮的功能有一些弊端,比如当一个DrawCall要求使用一个新的Material的时候,需要有大量的工作去处理,所以,你在一个场景中的Material越多,为了设置GPU端的数据而占用的CPU资源就越多。解决此问题的传统方法是减少DrawCall的数量以优化CPU渲染消耗,因为Unity在发出DrawCall之前必须进行很多设置。而且实际的CPU消耗就来自该设置,而不是来自GPU DrawCall本身,而这只是Unity需要将其推送到GPU命令缓冲区的一些字节而已。
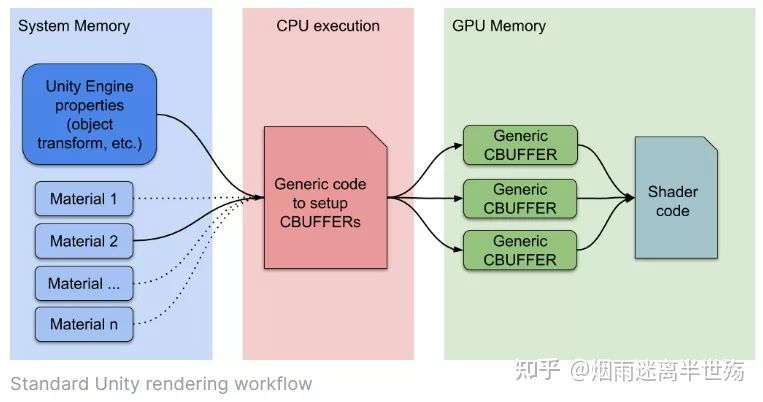
在渲染的循环中,当一个新的Material被发现了,CPU会收集所有的属性并且在GPU的内存中设置不同的Constant Buffers。GPU缓冲区的数量就取决于Shader是如何声明其CBUFFERs的。
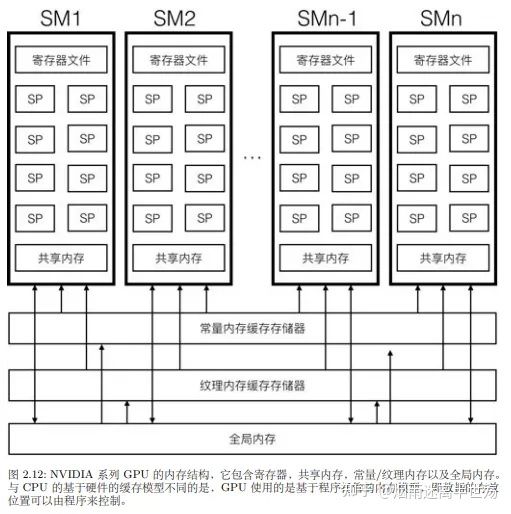
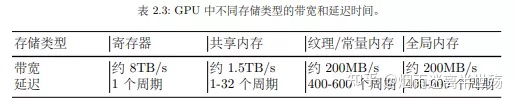
译者PS:上文提到的Constant Buffer对应于GPU上的一种常量内存缓存,速度仅次于流处理器族中的共享内存和寄存器,下图来自《全局光照技术》(手机拍照不好看,就pdf截图了)
SPR是如何工作的
当我们开发SRP的时候,我们不得不重写一些引擎的底层部分。这同样是一个好机会,我们可以原生地集成一些新的规范,例如GPU数据持久化。我们旨在加快场景使用大量不同材质(但Shader变体很少)的这种常见情况。
现在,底层的渲染Loop可以把material的数据持久化在GPU的内存。如果material的内容没有改变,我们就不需要设置,上传buffer到GPU。此外,我们使用特定的代码路径来在一个大的GPU buffer中快速的更新引擎的内置属性。现在这个新的流程图就像这样:
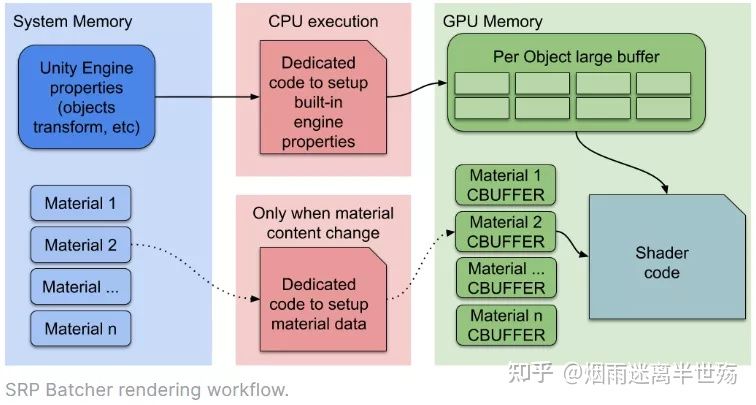
这样,CPU就只需要处理引擎内置的属性(例如标记为对象的变换的属性)。所有的Materials都在GPU内存上有一块持久化的CBUFFERs。综上所述,SRP Batcher加速来自于两个不同的方面:
- 每个材质的内容持久化在GPU的memory上
- 一个专用的代码路径来管理一个大的“per object”的GPU CBUFFER
如何启用SRP Batcher
你的工程必须使用URP,HDRP或者你的自定义SRP。然后就可以在SRP的Asset Inspector面板上进行激活
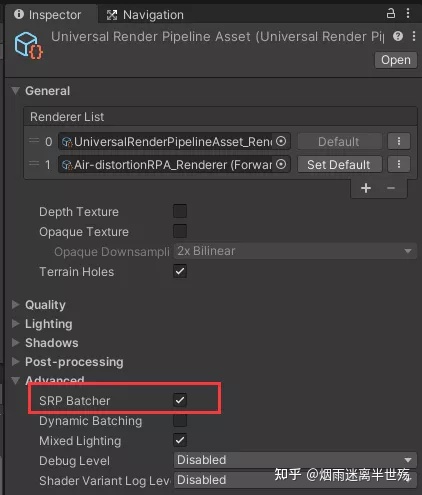
如果你想要在运行时使用代码来开关SRP Batcher:
1 | GraphicsSettings.useScriptableRenderPipelineBatching = true; |
SRP Batcher 兼容性
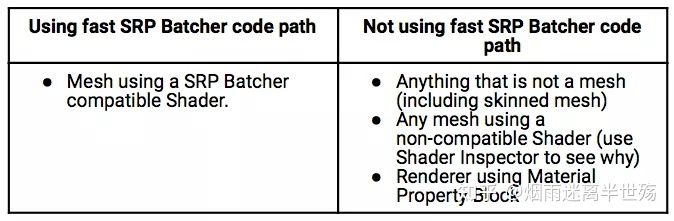
对于一个通过SRP Batcher代码路径渲染的对象,有三个要求
- 对象必须是Mesh或者Skinned Mesh,不能是粒子特效
- Shader必须与SRP Batcher兼容,所有的在URP或者HDRP中的Lit和Unlit Shader都满足这个需求(除了这些shader的粒子特效版本)
- 渲染的对象不使用MaterialPropertyBlocks
对于一个与SRP Batcher兼容的Shader来说:
- 必须声明所有引擎内置的属性(例如unity_ObjectToWorld,unity_SHAr等)在一个名称为“UnityPerDraw”的CBUFFER中。
- 必须声明所有的Material属性在一个名为“UnityPerMaterial”的CBUFFER中
可以在一个Shader的Inspector面板查看其是否兼容SRP Batcher
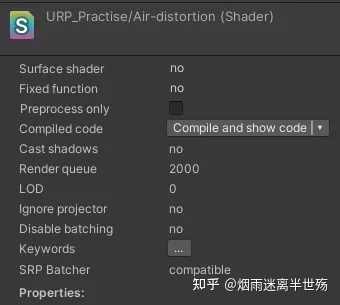
在一个给定的Scene中,一些对象时SRP Batcher兼容的,而另一些不是,这个场景仍然可以正常渲染。兼容SRP Batcher的对象使用SRP Batcher的代码路径,另一些将会使用标准的SRP渲染代码路径
性能监测的艺术
SRPBatcherProfiler.cs
如果你想在特定场景测试SRP Batcher带来的性能提升,可以使用SRPBatcherProfiler.cs这一C#脚本(这是链接)。
只需要把这个脚本加入你的场景,当游戏运行时,你就能看到一个UI面板,上面记录了一些有用的信息。你还可以使用F9来开关SRP Batcher

在这里,所有时间均以毫秒(ms)为单位。这些时间测量结果显示了在Unity SRP渲染循环中CPU消耗。
注意:计时表示在一帧期间调用的所有“RenderLoop.Draw”和“Shadows.Draw”标记的累计时间(所有线程)。例如“1.31ms SRP Batcher code path”,也许只有0.31ms花费在主线程,1ms的是所有的Graphic JobSystem的消耗。
| 名称 | 描述 |
|---|---|
| (SRP batcher ON) / (SRP batcher OFF) | 表示是否开启SRP Batcher,按F9开关 |
| CPU Rendering time | 表示SRP循环在CPU中花费的总的时间,无论使用哪种多线程模式,例如单线程,client/worker或Graphic Job。在这里,您可以最大程度地看到SRP Batcher的效果。要查看批处理程序的优化,请尝试将其打开和关闭以查看CPU耗时的差异。此示例总计为2.11ms。**(incl RT idle):**表示SRP在渲染线程空闲状态耗时。这可能意味着该应用程序处于client/worker模式,没有任何图形工作,这是在渲染线程必须等待主线程上的渲染命令时发生的。在此示例中,渲染线程空闲了0.36毫秒。 |
| SRP Batcher code path (flushes) | 表示您的游戏或应用程序花费在SRP Batcher代码路径中的时间。这可分为游戏渲染所有对象(shadow passes除外)所花费的时间(1.18ms),以及Shadows(1.13ms)。如果Shadows耗时很高,请尝试减少“场景”中的阴影投射灯数量,或者在“Render Pipeline Asset”中选择较低的Shadow Cascades数量。在这个例子中,它是1.31ms。**(flush(s))**数量表示Unity刷新场景的次数,因为它遇到了新的Shader Variant(在此示例中:89)。较少的flush总是更好的,因为这意味着一个渲染帧中的Shader Variants数量较少。 |
| Standard code path (flushes) | 表示Unity花费在渲染与SRP Batcher不兼容的对象(例如粒子)上的时间。在此示例中,SRP Batcher在0.80ms内flush了81个对象:shadow passes为0.09毫秒,所有其他pass为0.71毫秒。 |
| Global Main Loop: (FPS) | 表示全局主循环时间(以毫秒为单位),可以得知每秒帧数(FPS)。注意:“FPS”不是线性的,因此,如果您看到FPS增加20,这并不一定意味着您已经优化了场景。要查看SRP Batcher是否优化了场景渲染,请将其切换为“开”和“关”,然后在CPU Rendering time下比较数字。 |
示例:(译者PS:对于flushes数据变动,个人认为是在SRP Batcher关闭的时候,遇到一个不同材质的就会flush一次,而开启SRP Batcher,flushes值就取决于Shader变体了)
支持的平台
SRP几乎支持所有的平台,下面是一张表,包含了最低Unity版本信息
| Platform | Minimum Unity version required |
|---|---|
| Windows DirectX 11 | 2018.2 |
| PlayStation 4 | 2018.2 |
| Vulkan | 2018.3 |
| OSX Metal | 2018.3 |
| iOS Metal | 2018.3 |
| Nintendo Switch | 2018.3 |
| Xbox One DirectX 11 | 2019.2 |
| OpenGL 4.2 and higher | 2019.1 |
| OpenGL ES 3.1 and higher | 2019.1 |
| Xbox One DirectX 12 | 2019.1 |
| Windows DirectX 12 | 2019.1 |
VR那点事
SRP Batcher支持VR,但仅限于“SinglePassInstanced”模式,开启VR模式并不会增加任何CPU消耗
常见问题
我怎么知道我当前用法是否是SRP Batcher的最佳实践呢?
使用SRPBatcherProfiler.cs,首先检查SRP Batcher是否开启,然后查看“Standard code path”消耗,应该尽可能接近0。当然了,如果你的场景使用了一些skinned meshes或者粒子特效,“Standard code path”会不可避免的有一些消耗。
无论是否开启SRP Batcher,SRPBatcherProfiler耗时显示都差不多是为啥?
首先,您应该检查几乎所有渲染耗时都使用了SRP Batcher的代码路径(请参见上文)。如果是这样,数字仍然相似,则查看“flush”数字。当SRP Batcher打开时,“flush”数量应减少很多。根据经验,减少10倍非常好了,减少2倍也可以接受。如果flush计数没有减少很多,则意味着您仍然有很多Shader变体。尝试减少Shader变体的数量。如果您做了很多不同的着色器,请尝试使用更多参数制作一个“Uber”着色器。这样就无需拥有大量不同的Material参数。
当我开启SRP Batcher的时候并没有显著变化是为啥?
先看下上面的两个问题。如果SRPBatcherProfiler显示“CPU Rendering time”快两倍,并且FPS不变,则CPU渲染部分不是您的瓶颈。这并不意味着您不是CPU bound,而是因为您可能使用了太多的C# Gameplay或太多的物理元素。无论如何,如果“CPU Rendering time”快两倍,那还是不错的。您可能已经在顶部视频中注意到,即使以3.5倍的速度进行加速,场景仍然保持60FPS的速度。那是因为我们已将VSYNC打开。SRP Batcher确实在CPU端节省了6.8ms。这些毫秒可以用于其他任务。它还可以节省移动设备的电池寿命。
如何高效的检查SRP Batcher
理解“batcher”在SRP Batcher上下文中含义是很重要的。
传统做法,人们倾向于减少DrawCall的数量以优化CPU渲染消耗。这样做的真正原因是引擎在发出DrawCall之前必须进行很多设置。而且实际的CPU消耗来自该设置,而不是来自GPU DrawCall本身(这只是要放入GPU命令缓冲区的一些字节)。SRP Batcher不会减少DrawCalls的数量。它只是减少了DrawCall之间的GPU设置成本。
您可以在以下工作流程中看到这一点:

左侧是标准SRP渲染管线循环。右边是SRP Batcher循环。在SRP Batcher程序上下文中,“batch”只是“Bind”,“Draw”,“Bind”,“Draw”…这样的一个GPU命令的序列。
在标准SRP中,对于每种新material都调用慢的一批的SetShaderPass。在SRP Batcher上下文中,将为每个新的Shader变体调用SetShaderPass。
为了获得最佳性能,您需要将这些batches保持尽可能大。因此,您需要避免任何Shader变体更改,但是如果它们使用相同的Shader,则可以使用任意数量的不同materials。
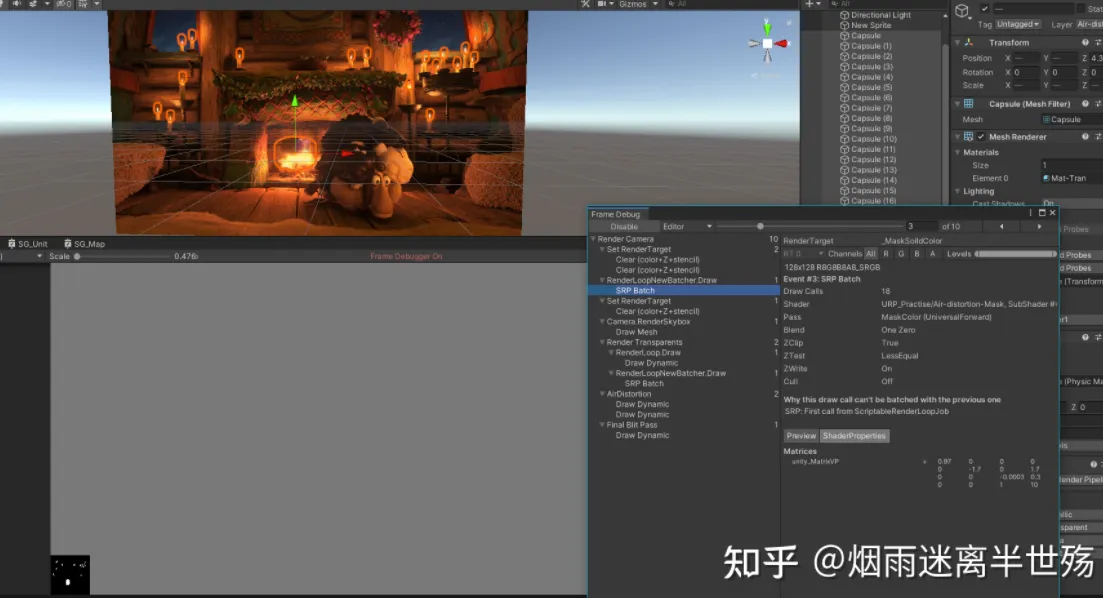
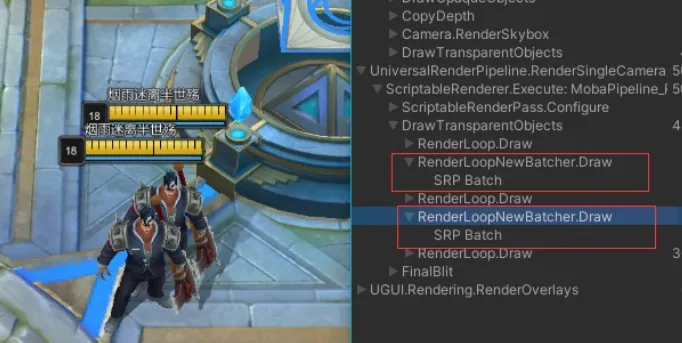
您可以使用Unity Frame Debugger查看SRP Batcher的“batches”长度。每个批次都是帧调试器中称为“ SRP Batch”的事件,如您在此处看到的:
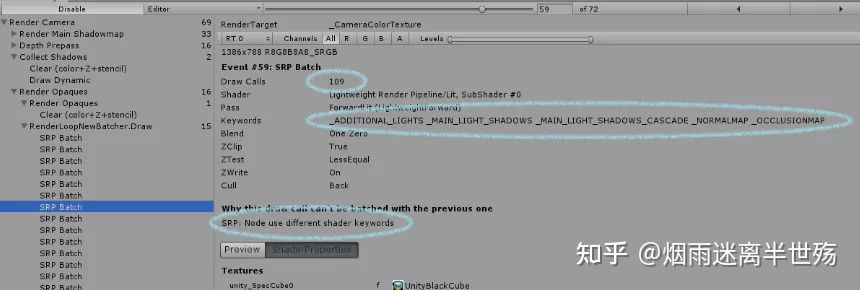
查看左侧的SRP Batch事件。另外查看batch的大小,即Drawcall的数量(此处为109)。这是一个非常有效的batch。您还将看到上一个batch被破坏的原因(“Node use different shader keywords”)。这意味着用于batch的Shader关键字不同于先前batch中的关键字。这意味着shader变体已更改,我们必须中断该batch。
在某些场景中,某些batch大小可能会非常低,例如以下示例:
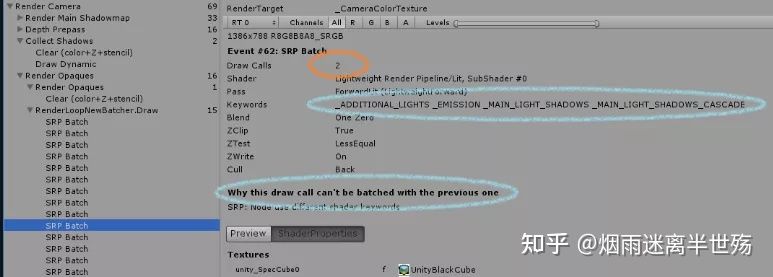
batch大小仅为2。这可能意味着您有太多不同的shader变体。如果要创建自己的SRP,请尝试使用最少的关键字编写通用的“Uber Shader”。您不必担心在“property”部分中输入了多少material参数。
注意:Frame Debugger中的SRP Batcher信息需要Unity 2018.3或更高版本。
编写你自己的SRP Batcher兼容的Shader
注意:此部分是专门给高级用户看的,他们会编写他们自己的SRP和Shader库。如果使用我们提供的管线(URP,HDRP)的用户可以跳过,我们提供的Shader是SRP Batcher兼容的。
如果你正在编写自己的渲染循环,你的shader需要遵循以下几条规则来受益于SRP Batcher
“Per Material”变量
首先,所有的“per material”数据都需要声明在一个名为“UnityPerMaterial”的CBUFFER中。什么是“per material”数据呢?其实就是你定义在“shader property”中所有的变量。这些变量可以显示在material的Inspector面板上。举个例子:
1 | Properties |
如果你编译这个Shader,这个Shader的Inspector面板将会这样显示:
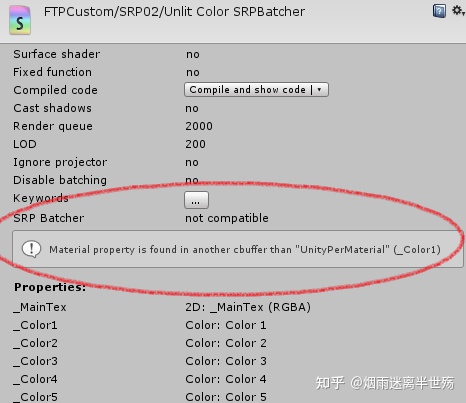
为了修复这个问题,仅仅需要这样声明即可
1 | CBUFFER_START(UnityPerMaterial) |
“Per Object”变量
SRP Batcher同样需要一个名为“UnityPerDraw”的CBUFFER。这个CBUFFER应该包含所有的Unity引擎 built-In的变量
变量声明顺序同 “UnityPerDraw” CBUFFER一样重要。所有变量都应遵循我们称为“Block Feature”的布局。例如,“Space Position block feature”应按以下顺序包含所有这些变量:
1 | CBUFFER_START(UnityPerDraw) |
如果不需要它们,则不必声明其中的某些block features。“UnityPerDraw”中的所有引擎内置变量应为float4或float4x4。在移动设备上,人们可能想使用real4(16位编码的浮点值)来节省一些GPU带宽。并非所有UnityPerDraw变量都可以使用“real4”。请参考“Could be real4”一栏。
下表描述了可以在“UnityPerDraw” CBUFFER中使用的所有可能的block features:
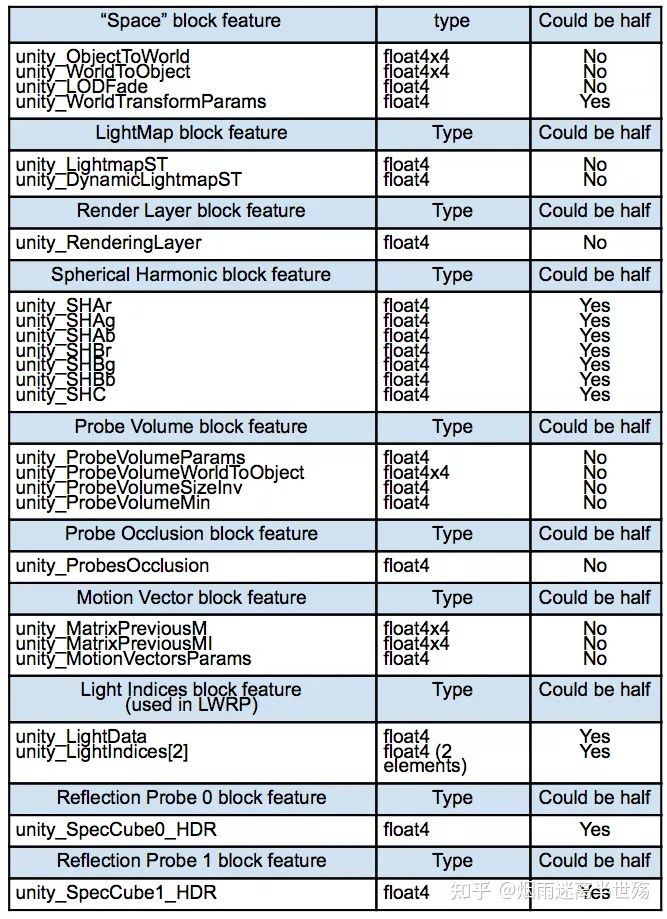
注意:如果将一个feature block的变量之一声明为real4(half),则该feature block的所有其他潜在变量也应声明为real4。
提示1:始终在Inpsector中检查新shader的兼容性状态。我们检查了几个潜在的错误(UnityPerDraw布局声明等),并显示为什么不兼容。
提示2:在编写自己的SRP Shader时,可以参考LWRP或HDRP包以查看其UnityPerDraw CBUFFER声明以获取灵感。
参考
https://blogs.unity3d.com/2019/02/28/srp-batcher-speed-up-your-rendering/
 微信
微信 支付宝
支付宝