Unity Shader入门精要学习笔记:Unity中的渲染优化技术
影响性能的因素
对于一个游戏来说,它主要需要使用两种计算资源,CPU和GPU,他们会互相合作,来让我们游戏可以在预期的帧率和分辨率下工作。
所以,我们可以把造成游戏性能瓶颈的主要原因分成以下几个方面
-CPU
– 过多的draw call
– 复杂的脚本或者物理模拟
-GPU
– 顶点处理
– - 过多的顶点
– - 过多的逐顶点计算
– 片元处理
– - 过多的片元
– - 过多的逐片元计算
-带宽
– 使用了尺寸很大且未压缩的纹理
– 分辨率过高的帧缓存
对于CPU来说,限制它的主要是每一帧中draw call的数目,draw call简单来说就是CPU在每次通知GPU进行渲染之前,都需要提前准备好顶点数据(如位置,法线,颜色,纹理坐标等),然后调用一系列API把它们放到GPU可以访问的指定位置,最后调用一个绘制命令,而调用绘制命令时,就会产生一个draw call,过多的draw call会造成CPU的性能瓶颈。
对于GPU来说,它负责整个渲染流水线,它从处理CPU传递过来的模型数据开始,进行顶点着色器,片元着色器等一系列工作,最后输出屏幕上的每个像素,因此CPU的性能瓶颈和需要处理的顶点数目,屏幕分辨率,显存等因素有关,相关的优化策略可以从减少处理的数据规模(包括顶点数目和片元数目),减少运算复杂度等方面入手。
相对应的,就衍生出很多优化技术
-CPU优化
– 使用批处理技术减少draw call数目
-GPU优化
– 减少需要处理的顶点数目
— 优化几何体
— 使用遮挡剔除技术
— 使用模型的LOD(多细节层次)技术
– 减少需要处理的片元数目
— 控制绘制顺序
— 警惕透明物体
— 减少实时光照
– 减少计算复杂度
— 使用Shader的LOD技术
— 代码方面的优化
-节省内存带宽
– 减少纹理大小
– 利用分辨率缩放
Unity中的渲染分析工具
Rendering Statistics Window
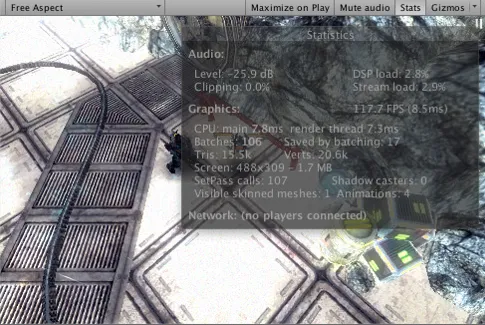
- Time per frame and FPS:处理和渲染一个游戏帧所花费的时间(以及相应的每秒帧数)。注意,这个数字只包括做帧更新和渲染游戏视图所花费的时间;它不包括在编辑器中绘制Scene视图、Inspector和其他只针对编辑器的处理所花费的时间。
- Render thread:GPU渲染线程处理图像所花费的时间,具体数值由GPU性能来决定。
- Batches:“批处理”是指引擎试图将多个对象的渲染合并到一块内存中,以减少由于资源切换造成的CPU开销,Batches就是合并后的DrawCall次数
- Saved by batching:合并的批次数。为了确保良好的批处理,您通常应该尽可能在不同对象之间共享材质。更改渲染状态将会将批次破坏分解为具有相同状态的组。
- Tris and Verts:绘制的三角形和顶点的数量。这在优化低端硬件时非常重要
- Screen:屏幕的大小,以及它的抗锯齿水平和内存使用情况。
- SetPass:渲染使用Pass的次数。每个Pass都需要Unity运行时绑定一个新的着色器,这可能会增加CPU开销。
- Visible Skinned Meshes:所渲染的蒙皮网格的数量。
- Animations:播放的动画数量。
- Shadow casters:表示场景中有多少个可以投射阴影的物体,一般这些物体都作为场景中的光源。
Rendering Profiler
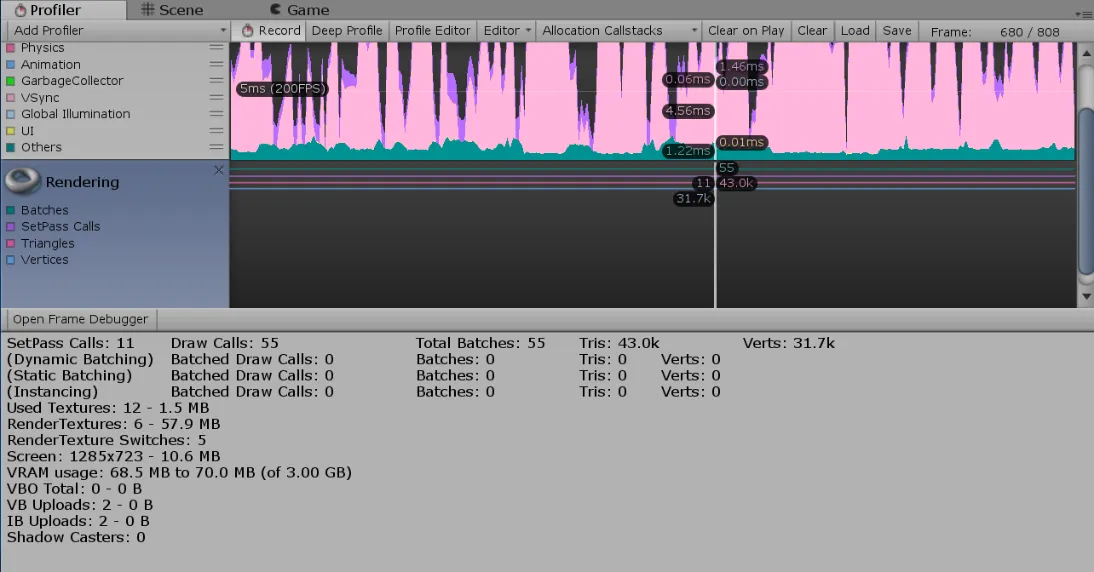
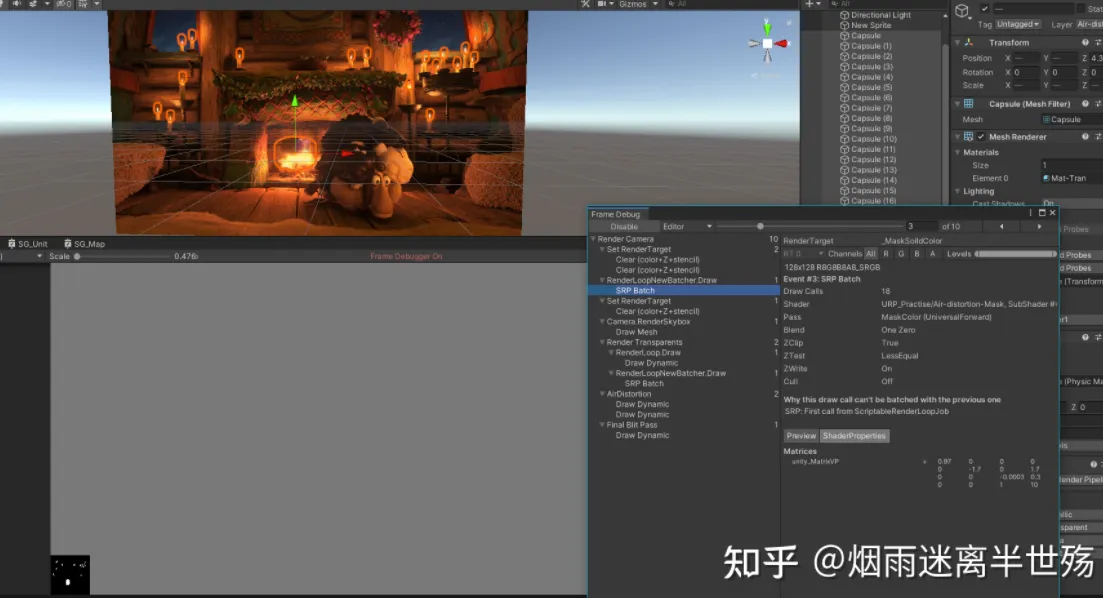
Frame Debugger
https://docs.unity3d.com/Manual/FrameDebugger.html
其他性能分析工具
对于安卓:高通的Adreno,英伟达的NVPerfHUD
对于IOS:PowerVRAM的PVRUniSCo shader
其他还有
Visual Studio graphics debugger
Intel GPA
RenderDoc
NVIDIA NSight
AMD GPU PerfStudio
Xcode GPU Frame Capture
GPU Driver Instruments
减少draw call数目
批处理的目的就是为了减少每一帧需要的draw call数目。为了把一个对象渲染到屏幕上,CPU需要检查哪些光源影响了该物体,绑定shader并设置它的参数,再把渲染命令发送给GPU。
使用同一个材质的物体可以进行批处理,这是因为,对于使用同一个材质的物体,他们之间的不同只是顶点数据的差别,我们可以把这些顶点数据合并在一起,再一起发送给GPU,就可以完成一次批处理。
动态批处理
基本原理是:每一帧把可以进行批处理的模型网格进行合并,再把合并后的模型数据传递给GPU,然后使用同一个材质进行渲染。经过动态批处理的物体仍然可以移动,这是由于在处理每帧时Unity都会重新合并一次网格。
多Pass的shader会中断批处理,在前向渲染中,我们有时需要使用额外的Pass为模型添加更多光照效果,这样模型就不会被批处理了。
静态批处理
它的实现原理是,只在运行开始阶段,把需要进行静态批处理的模型合并到一个新的网格结构中,这意味着这些模型不可以在运行时刻被移动。
由于他只需要进行一次合并操作,因此比动态批处理更加高效。
静态批处理需要占用更多的内存来存储合并后的几何结构。
共享材质
如果两个材质之间只有使用的纹理不同,我们可以把这些纹理合并到一张更大的纹理中,这张更大的纹理叫做图集(Atlas),一旦使用了同一张纹理,我们就可以使用同一个材质,再使用不同的采样坐标对纹理采样即可。
有时不同的物体在材质上还有一些微小的参数变化,例如颜色不同,某些浮点属性不同,但是,不管动态批处理还是静态批处理,他们前提都是要使用同一个材质,也就是说他们指向的材质必须是同一个实体。
我们可以把想要调整的参数存入网格顶点数据,例如,森林场景中所有的树使用了同一种材质,我们希望他们可以通过批处理来减少draw call,但是不同树的颜色可能不同,这是我们可以使用网格的顶点颜色数据进行调整。
减少需要处理的顶点数目
优化几何体
Unity是站在GPU的角度去计算顶点数的,有时需要把一个顶点拆分成多个顶点,原因主要有两个:分离纹理坐标,产生平滑的边界。本质就是,对于GPU来说,顶点的每一个属性和顶点之间必须是一对一的关系。
所以,尽可能减少顶点数目才是我们需要关心的地方,此外,还需要移除不必要的硬边以及纹理衔接,避免边界平滑和纹理分离。
模型LOD技术
它的原理是,当一个物体离摄像机很远时,模型上的很多细节是无法被察觉到的。
遮挡剔除技术(Occlusion culling)
遮挡剔除技术可以用来消除那些在其他物件后面看不到的物件,这意味着资源不会浪费在计算那些看不到的顶点上。
注意他和视锥体剔除(Frustum Culling)之间的区别,视锥体剔除只会剔除掉那些不在摄像机视野范围内的对象,但不会判断视野中是否有物体被其他物体挡住,而遮挡剔除会使用一个虚拟的摄像机来遍历场景,从而构建一个潜在可见对象集合的层级结构。
减少需要处理的片元数目
另一个造成GPU瓶颈的是需要处理过多的片元,这部分优化重点在于减少overdraw,overdraw就是同一个像素被绘制了多次。
控制绘制顺序
由于深度测试的存在,如果我们可以保证物体都是从前往后绘制的,就可以很大程度减少overdraw,这是因为,在后面绘制的物体由于无法通过深度测试,就不会再进行后面的渲染处理。
在Unity中,渲染队列数目小于2500的(Background,Geometry,AlphaTest)对象被人物是不透明物体,这些物体总体上是从前往后绘制的。而使用其他队列(Transparent,Overlay)的物体,则是从后往前绘制的。我们可以尽可能把物体的队列设置为不透明渲染队列,而尽量避免半透明队列。
时刻警惕透明物体
对于半透明对象来说,由于它们没有开启深度写入,因此如果要得到正确的渲染结果,就必须从后往前渲染,就意味着,半透明物体几乎一定会造成overdraw。
在移动平台上,透明度测试也会影响游戏性能,虽然透明度测试没有关闭深度写入,但是由于它的实现使用了discard或clip操作,这些操作会导致一些硬件的优化策略失效。
减少实时光照和阴影
实时光照有可能提高draw call和overdraw,因为对于逐像素光源来说,被这些光源照亮的物体需要再渲染一次,无论是静态批处理还是动态批处理,对于这种额外处理逐像素光源的Pass都无法进行批处理,他们会中断批处理。
游戏中往往使用了烘焙技术,把光照提前烘焙到一张光照纹理中,然后运行是只需要根据纹理采样得到光照结果即可。
在移动平台上,一个物体使用的逐像素光源数目应小于1(不包括平行光),如果一定要使用更多实时光照,可以用逐顶点光照替代。
阴影的处理同理。
节省带宽
大量使用未经压缩的纹理以及使用过大的分辨率都会造成由于带宽而引发的性能瓶颈。
减少纹理大小
纹理长宽比尽量是2的整数幂
使用多级渐远纹理技术和纹理压缩
利用分辨率缩放
Screen.SetResolution
减少计算复杂度
Shader的LOD技术
与模型的LOD技术类似,Shader的LOD技术可以控制使用的Shader等级,原理是,只有Shader的LOD值小于某个设定的值,这个Shader才会被使用,而使用了那些超过设定值的Shader的物体将不会被渲染。
通常使用以下语句来指明Shader的LOD值
1 | SubShader |
在Shader的导入面板也能看到Shader的LOD值。
代码方面的优化
游戏中数目排序:对象数<顶点数<像素数,所以我们应该尽可能把计算放在每个对象或逐顶点上。
尽可能使用低精度的浮点值进行计算,
最高精度的float/highp适用于存储诸如顶点坐标等变量,但他的计算速度是最慢的,我们应该尽量避免在片元着色器中使用这种精度进行计算。
half/mediump适用于一些标量,纹理坐标等变量,它的计算速度大约是float的两倍。
fixed/lowp适用于绝大多数颜色变量和归一化后的方向矢量,在进行一些对精度要求不高的计算时,我们应该尽量使用这种精度的变量,它的计算速度大约是float的4倍。注意避免对这些低精度变量进行频繁的swizzle操作(如color.xwxw),尽量避免在不同精度之间的切换,这可能会造成一定的性能下降。
在使用插值寄存器把数据从顶点着色器传递给下一个阶段时,我们应该使用尽可能少的插值变量。例如,如果需要对两个纹理坐标进行插值,通常会把它们打包在同一个float4类型的变量中,两个纹理坐标分别对应xy分量和zw分量。
尽可能不要使用全屏的屏幕后处理效果,如果实在要用就用fixed/lowp进行低精度计算(纹理坐标除外,可以使用half/mediump)。
那些高精度的运算可以使用查找表(LUT)或者转移到顶点着色器中进行处理。
尽量把多个特效合并到一个Shader中,例如我们把颜色校正和添加噪声等屏幕特效在Bloom特效的最后一个Pass中进行合成。
尽可能不要使用分支语句和循环语句
尽可能避免使用类似sin,tan,pow,log等较为复杂的数学运算,我们可以使用查找表来作为替代。
尽可能不要使用discard操作,因为这会影响硬件的某些优化。
扩展阅读
Unity官方移动平台优化指南:https://docs.unity3d.com/Manual/MobileOptimizationPracticalGuide.html
![微信]() 微信
微信![支付宝]() 支付宝
支付宝