
FEAR基于GOAP的AI系统GDC分享(中英双语)
前言
经过前一篇对于GitHub开源库ReGoap的介绍,想必大家都对GOAP这一AI方案有一定的了解了,那么今天,我们就来更加深入的了解一下,FEAR这款游戏是如何运用GOAP技术的吧。
注:
- 正文中的
规划/计划系统字样一般都可以当做GOAP系统。 - 正文中的
动作/行为/操作字样一般都可以当做Action。 - 正文中的
效果/影响字样一般都可以当做Effect。 - 正文中的
目标/目的字样一般都可以当做Goal。 - 正文中的
记忆/内存字样一般都可以当做Memory。
资源链接
ReGoap开源库:https://link.zhihu.com/?target=https%3A//github.com/luxkun/ReGoap
ReGoap开源库中文文档:https://link.zhihu.com/?target=https%3A//www.lfzxb.top/goal-oriented-action-planning-chinese-document/
PDF链接:https://link.zhihu.com/?target=http%3A//alumni.media.mit.edu/~jorkin/gdc2006_orkin_jeff_fear.pdf
视频链接:https://link.zhihu.com/?target=https%3A//www.youtube.com/channel/UC0JB7TSe49lg56u6qH8y_MQ/search%3Fquery%3DFEAR
GOAP资源汇总:https://link.zhihu.com/?target=http%3A//alumni.media.mit.edu/~jorkin/goap.html
我的Goap开源库(多线程,JobSystem,路径规划算法优化):https://link.zhihu.com/?target=https%3A//gitee.com/NKG_admin/NKGGOAP
正文
If the audience of GDC waspolledto list the most common A.I. techniques applied to games,undoubtedly the top two answers would be A* and Finite State Machines(FSMs).Nearlyevery game that exhibits any A.I. at all uses some form of an FSM to control characterbehavior, and A* to plan paths.F.E.A.R.uses these techniques too, but in unconventionalways. The FSM for characters inF.E.A.R. has only three states, and we use A* to plansequences of actions as well as to plan paths.Thispaperfocuses on applying planning inpractice, usingF.E.A.R.as a case study. The emphasis is demonstrating how the planningsystem improvedthe process of developing character behaviors forF.E.A.R.
如果现场的观众们被要求列出应用于游戏的最常见的人工智能技术,那么毫无疑问,排在前两位的答案将是A*和有限状态机(FSMs)。几乎每一款展现人工智能的游戏都使用某种形式的FSM来控制角色行为,并使用A*来规划路径。FEAR也使用这些技术,但是并没有按照常规套路出牌。FSM的角色信息,只有三种状态,我们使用A*来计划操作序列和计划路径。本文以FEAR为例,着重阐述了规划在实践中的应用。作为一个案例研究。重点是演示该规划系统如何改进FEAR的角色行为这一发展过程。
We wantedF.E.A.R.to be an over-the-top action movie experience, with combat as intense asmultiplayer against a team of experienced humans.A.I.take cover, blind fire, dive throughwindows, flush outtheplayer withgrenades, communicate with teammates, and booley.com itseems counter-intuitive that ourstate machinewould have only three states.
我们想要把FEAR打造成一种顶级的动作电影体验并且战斗就像与一群有经验的人进行的多人游戏一样激烈。AI寻找掩护,进行扫射,从窗户中跳出来,用手榴弹轰炸玩家,和队友交流等等。尽管如此,我们的状态机可能只有三种状态,这似乎有违直觉。

三种状态
The three states in our state machine areGoto,Animate, andUseSmartObject.UseSmartObjectisan implementation detail of our systems at Monolith, and is reallyjust aspecialized data-driven version of theAnimatestate. Rather than explicitly telling it whichanimation to play, the animation is specified through aSmartObjectin the gamedatabase.Forthepurposesof this paper,we can just considerUseSmartObjectto be the same asAnimate.Sothat meanswe are really talking about anFSMwith only two states,GotoandAnimate!
状态机中的三个状态分别是Goto,Animate和UseSmartObject。UseSmartObject是Monolith系统上的细节实现,实际上只是Animate状态专用的数据驱动者。 具体来说就是在游戏中通过SmartObject来指定动画,而不是明确地告诉它要播放哪个动画。从本文的上下文来看,我们可以认为UseSmartObject与Animate相同。这意味着我们实际上是在谈论只有两个状态的FSM:Goto和Animate!
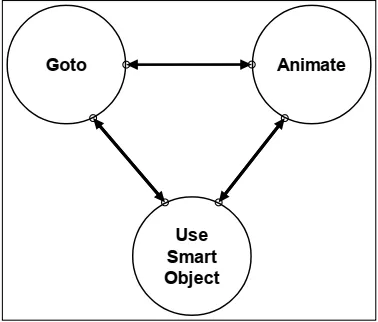
As much as we like to pat ourselves on the back, and talk about how smart our A.I.are, thereality is that all A.I.ever do is move around and play animations! Think about it. An A.I.goingfor cover is just moving to some position,andthen playing a duck or lean animation. An A.I.attacking just loops a firing animation. Sure there are some implementation details; weassume the animationsystem has key frameswhichmay have embedded messages that tellthe audio system to play a footstep sound, or the weapon system to start and stop firing, but asfar as the A.I.’sdecision-makingis concerned, heis just moving around or playing ananimation.
尽管我们喜欢胸有成竹的谈论我们的AI系统多么聪明,但现实是,人工智能所做的一切都是四处走动并播放动画!想一想。AI寻找掩体的过程只是移动到某个位置,然后播放躲避或伏身动画。 AI攻击只会循环触发动画。当然,有一些实现细节;我们假设动画系统具有关键帧,这些帧可能包含嵌入的消息,这些消息告诉音频系统播放脚步声,或者武器开始和停止发射,但就AI的决策而言,他只是在四处移动或播放动画。
In fact, moving is performed by playing an animation! And various animations (suchasrecoils,jumps, and falls) may move the character. So the only difference betweenGotoandAnimateis thatGotois playing an animation while heading towards somespecificdestination, whileAnimatejust plays the animation, which may have a side effect of moving the charactertosomearbitrary position.
实际上,移动是通过播放动画来执行的!并且各种动画(例如后撤,跳跃和跳下)可能会移动角色。因此,Goto和Animate之间的唯一区别是,Goto在朝某个特定目标前进的同时播放动画,而Animate只是在播放动画,这可能会导致将角色移动到任意位置的副作用。
The tricky part of modeling character behavior is determining when to switch between thesetwo states, and whatparameters to set. Which destination shouldthe A.I.go to? Where is thedestination? Which animation should the A.I.play? Should the animation play once, or should it loop?The logic determining when to transition from one state to another, and which parameters to specifyneedto live somewhere. This logic may be written directly into the C++ code of the states themselves, or may be external in some kind of table or script file, oritmaybe represented visually in some kind of graphical FSM visualization tool. However the logic is specified, in all of these cases it has to be specified manually by a programmer or designer.
架构角色行为的棘手部分是确定何时在两种状态之间切换以及设置哪些参数。 AI应该去哪个目的地? 目的地在哪里? AI应该播放哪个动画? 动画应该播放一次还是应该循环播放?逻辑确定何时从一种状态转换为另一种状态,以及指定要驻留在某个位置的参数。 该逻辑可以直接写入状态本身的C++代码中,或者可以在某种表或脚本文件中外部表示,或者可以在某种图形可视化工具中直观地表示。 但是,这些方式配置的逻辑都是确定性的的,都必须由程序员或设计人员手动指定。
管理复杂度
ForF.E.A.R., this is where planning comes in. We decided to move that logic into a planningsystem, rather than embedding it in the FSM as games typically have in the past. As you willsee in this paper, a planning system gives A.I.the knowledge they need to be able to maketheir own decisions about when to transition from one state to another. This relieves theprogrammer or designer of a burden that gets bigger with each generation of games.
对于FEAR,这是开始进行规划的地方。我们决定将这种逻辑转移到规划系统中,而不是像过去通常的游戏那样将其嵌入到FSM中。正如您将在本文中看到的那样,一个计划系统为AI提供了他们需要的知识,以便他们能够自行决定何时从一种状态过渡到另一种状态。这减轻了程序员或设计师在每次迭代游戏后越来越重的负担。
In the early generations of shooters,such asShogo(1998)players were happy if the A.I.noticed themat alland started attacking.By 2000, players wanted more, so we startedseeingA.I.that can take cover, and even flip over furniture to create their own cover.InNo One LivesForever(NOLF) 1 and 2, A.I.find appropriate cover positions from enemy fire, and thenpoprandomly in and out like a shooting gallery.Today, players expect more realism, tocomplement the realism of thephysics and lighting in theenvironments. InF.E.A.R.,A.I.usecover more tactically, coordinating with squadmembersto lay suppression fire while othersadvance. A.I.only leavecover when threatened, and blind fire if they have no better position.
在早期的射击游戏中,例如Shogo(1998),如果AI稍微注意到玩家就可以开始进攻,玩家会很高兴。到2000年,玩家们开始欲求不满,因此我们开始尝试设计可以躲藏甚至翻动家具来制造自己的掩体的AI。在《无人永生》(NOLF)1和2中,AI从敌人的火力中找到合适的掩护位置,然后像射击场一样随机进出(这里应该说的是靶场里的移动靶和随机靶)。今天,玩家期望更多的真实感,来二配合环境中物理和照明的真实感。 在FEAR中的AI在战术上更有效地利用掩护,与小队协调比如一些人进行火力压制,而其他人则前进。 AI仅在受到威胁时才离开掩体,如果他们没有更好的位置,则开始亡命扫射。
With each layer of realism, the behavior gets more and more complex. The complexityrequired fortoday’sAAA titles is getting unmanageable.Damian Isla’s GDC 2005 paper aboutmanaging complexity in the Halo 2 systems gives further evidence that is a problem alldevelopers are facing[Isla 2005].This talk could be thought of as a variation on the themeofmanaging complexity. Introducing real-time planning was our attempt at solving the problem.
为了实现更加真实的游戏世界,AI行为变得越来越复杂。当今的3A游戏所要求的复杂性变得更加难以控制。Damian Isl在GDC 2005上发表的有关在《光晕2》系统中管理复杂性的论文进一步证明了所有开发人员都面临的问题。引入实时计划是我们解决这类问题进行的尝试。
This is one of the main take a ways of this paper: It’s not that any particular behavior in F.E.A.R.could not be implemented with existing techniques. Instead, it is the complexity of the combination and interaction of all of the behaviorsthat becomes unmanageable.
这是本文的主要内容之一:并不是说,FEAR无法使用现有技术实现功能。相反,正式因为这些变得越来越难以控制的行为组合和互动,才让我们决定不使用现有的这些技术。
对比FSM和规划
Let’s compareFSMsto planning. An FSMtells an A.I.exactlyhow to behave in every situation. A planning system tells the A.I.what his goals and actions are, and lets the A.I.decide how to sequence actions to satisfy goals.FSMs are procedural, while planning is declarative.Later we will seehow wecanuse these twotypes ofsystems together tocomplement one another.
让我们比较一下FSM和规划。 FSM会告诉AI在每种情况下的准确举止。一个规划系统告诉AI他的Goal和Action是什么,让AI决定如何对行动进行选择排序以达到目标,FSM是过程式的,而规划是声明式的(意思就是只声明Action,Goal,然后让系统自己组合方案)。稍后我们将看到如何将这两种类型的系统一起使用来取长补短。
The motivation to explore planning came from the fact that we had only one A.I. programmer,but there are lots of A.I.characters.The thought was that if we can delegate some of the work load to these AI guys, we’dbe in good shape. If we want squad behavior in addition to individual unit behavior, it’s going to take more man-hours to develop. If the A.I.are really sosmart, and they can figure out some things on their own, then we’ll be all set!
探索规划的动机来自于我们只有一个AI程序员的事实。但是有很多AI对象。我们的想法是,如果我们可以将一些工作负载委派给这些AI对象,那么我们的AI程序员就可以活下来。如果除了个人单位行为之外,我们还希望群体行为,那么将需要更多的时间进行开发。如果AI对象真的很聪明,并且他们可以自己弄清楚一些事情,那么我们就起飞了!
Before we continue, we should nail down exactly what we mean by the termplanning.Planning is a formalized process of searching for sequence of actions to satisfy a goal.The planning process is called planformulation.The planning system that we implemented for FEAR most closely resembles the STRIPS planning system from academia.
在继续之前,我们应该确切地了解术语规划的含义。规划是一种形式化的过程,用于搜索要满足目标的行动序列。规划过程称为计划制定。我们为FEAR实施的规划系统与之最为相似的是来自学术界的STRIPS计划系统。
STRIPS规划的简单介绍
STRIPS was developedat StanfordUniversityin 1970, and the name is simply an acronym forthe STanford Research Institute Problem Solver.STRIPS consists of goals and actions,where goals describe some desired state of the world towe want toreach, and actions aredefined in terms of preconditions and effects. An action may only execute ifall of itspreconditions are met, and each action changes the state of the world in some way.[Nilsson1998, and Russell & Norvig 2002].
STRIPS是由斯坦福大学(StanfordUniversity)于1970年开发的,名称是斯坦福研究所问题解决者(Stanford Research Problem Solver)的首字母缩写。 一个Action只有在其所有前提条件都得到满足的情况下才能执行,并且每个动作都会以某种方式改变世界的状态。[Nilsson 1998,Russell&Norvig 2002]。
When we talk aboutstatesin the context of planning, we mean something different than theway we think about states in an Flying Spaghetti Monster | Italian Restaurant the context of an FSM, we’re talking about proceduralstates, which update and run code to animate and make decisions; for example anAttackstate or aSearchstate.In a planning system, we represent the state of the world as aconjunction of literals. Another way to phrasethisis to say that we represent the state of theworld as an assignment to some set of variables that collectively describe the world.
当我们在规划上下文中谈论状态的含义与我们在FSM中状态的含义有所不同。在FSM中,我们所谈论的是过程状态,该过程状态用于更新和运行代码以进行动画处理和决策。 例如Attackstate或Searchstate,在规划系统中,我们将世界状态表示为文字的结合。 这句话的另一种说法是说,我们将世界状态表示为对共同描述世界的某些变量集的赋值。
Let’s say we wanted to describe a state of the world where someone is at home and wearing a tie. We can represent it as a logical expression,like this:
让我们想象,当前要描述一个世界的状态:一个人在家里并且正在打领带,我们可以用下面这个逻辑表达式来描述:
AtLocation(Home) ^ Wearing(Tie)
Or as an assignment to a vector of variable values, like this:
或者作为一个变量赋值
(AtLocation, Wearing) = (Home, Tie)
Looking at another example,if we are trying to represent the state of the world in the game Lemonade Stand, we’ll need a vector of variables that keeps track of the weather, number oflemons, and amount of money we have. At differentpoints in time, the weather may be sunnyor rainy. We may have various numbers of lemons, and various amounts of money. It’s worthnoting that some of these variables have an enumerated discrete(e.g. sunny or rainy)set ofpossible values, while othersarecontinuous (e.g. any number of lemons).Our goal stateforthis gamewill be one where we have lots of money. Any value assigned to weather andnumber of lemons will be Ok.
再看一个例子,如果我们试图在柠檬水摊位游戏中代表世界的状况,我们将需要一个变量组来跟踪天气,柠檬数量和所拥有的资金。在不同的时间点,天气可能是晴天或多雨。我们可能有各种各样的柠檬,还有各种各样的钱。值得注意的是,其中一些变量具有枚举的离散值(例如,晴天或下雨),而其他变量则是连续的(例如,任意数量的柠檬)。此游戏的目标状态是我们有很多钱。分配给天气和柠檬数量的任何值都可以。
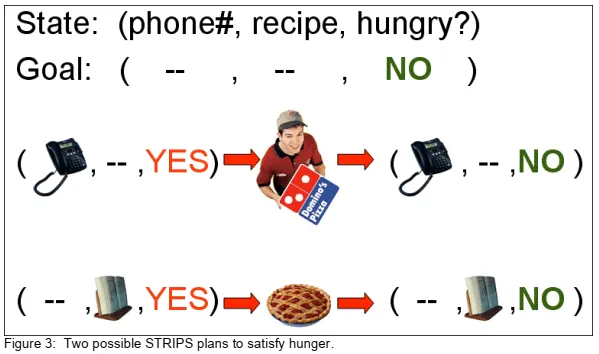
Now, let’s look atan example ofhowtheSTRIPSplanning processworks. Let’s say that Almais hungry.Alma could call Domino’s and order a pizza, but only if she has the phone numberforDomino’pizza Montpellier livraison | Pizzas Gourmandes | formule boisson dessert | commande en ligne is not her only option, however;she could also bake a pie, butonly shehas a recipe.So, Alma’sgoalis to get to a stateof the world where she is not hungry. Shehas twoactionsshe can take to satisfy that goal: calling Domino’s or baking a pie. If she iscurrently in a state of the world where she has the phone number for Domino’s, then she canformulate the plan of calling Domino’s to satisfy her hunger. Alternatively, if she is in the stateof the world where she has a recipe, she can bake a pie.If Alma is in the fortunate situationwhere she has both a phone number and a recipe, either plan is valid to satisfy thegoal. We will talk later about ways to force the planner to prefer one plan over another. If Alma hasneithera phone number nora recipe, she is out of luck; there is no possible plan that can beformulated to satisfy her hunger.These examples show trivially simple plans with only oneaction, but in reality a plan may have an arbitrary number of actions, chained by preconditionsand effects. For instance, if ordering pizzahasa precondition that Alma has enough money,the satisfying plan may require first driving to the bank.
现在,让我们看一个有关STRIPS计划过程如何工作的例子。假设阿尔码饿了,阿尔玛可以打电话给多米诺订购披萨,但前提是他有多米诺骨牌的电话号码,但披萨并不是她唯一的选择;她也可以烤馅饼,但要有食谱。所以他的目标就是不再饥饿。她可以采取两种行动来实现该目标:打电话给Domino或烤馅饼。如果她目前的世界状态拥有多米诺的电话号码,那么她可以制定呼叫多米诺的计划,以缓解自己的饥饿感。或者,如果她世界状态有食谱,可以烤馅饼。如果Alma处于幸运的情况下,她既有电话号码又有食谱,则两种计划都可以满足目标。稍后我们将讨论迫使计划者偏爱一个计划而不是另一个计划的方法。如果Alma没有电话号码或者食谱,那么她很不幸;这些示例显示了只有一个动作的简单计划,但实际上一个计划可能具有任意数量的动作,这些动作受先决条件和效果的束缚。例如,如果订购披萨店的先决条件是阿尔玛有足够的钱,那么令人满意的计划可能需要先开车到银行。
We have previously describedthatagoal in STRIPSdescribes some desired state of the worldthat we want to reach. Now we will describe anaction. A STRIPSaction is defined by itspreconditions andeffects. Thepreconditions are described in terms of the state of the world,just like we defined ourgoal. Theeffects are described with list of modifications to the state ofthe world. First the Delete List removes knowledge about the world.Then,the Add List addsnew knowledge. So, theeffects of theOrderPizzaaction first remove knowledge that Almais hungry, then adds knowledge that she is not hungry.
我们之前已经在STRIPS中描述了目标,它描述了我们想要达到的某些理想状态。现在我们将描述一个动作。 STRIPS的动作由其前提条件和效果定义。前提条件是根据世界状况描述的,就像我们定义目标一样。通过对世界状况的修改列表来描述效果。首先,删除列表删除有关该世界的信息。然后,添加列表添加新信息。因此,OrderPizza动作的效果首先删除了Almais饥饿的信息,然后添加了她不饥饿的信息。
It may seem strange that we have to delete one assignment to the value ofHungry, and thenadd another, rather than simply changing the value. STRIPSneedsto do this, because thereis nothing in formal logic to constrain a variable toonlyone value. Ifthe value ofHungrywaspreviouslyYES, andthe effectofOrderPizzais simply to add knowledge thatHungryis nowset toNO, we will end up with a state of the world whereHungryis bothYESandNO.We canimagine anaction where this behavior is desirable. For example, theBuyaction addsknowledge to the state of the world that we nowownsome object. We may be able tobuyanarbitrary number of objects.Owningone object does not prevent us fromowninganother.
我们不得不删除一个分配给Hungry的值,然后添加另一个值,而不是简单地更改值,这似乎很奇怪。 STRIPS就是需要这样做,因为逻辑中没有将变量约束为仅一个值的方法。如果“Hungry”的值以前是“是”,而“OrderPizza”的效果只是增加了“Hungry”为“否”的信息,那么我们将得出一个世界状态,其中“饥饿”既是“是”又是“否”。我们可以想象一个需要这种行为的行动。例如,“购买”操作向我们现在拥有的某些对象的世界状态添加了信息。我们也许可以购买任意数量的对象。拥有一个对象并不能阻止我们拥有另一个。
The state of the world at some point may reflect that we own coins, a key, and a sword.Back to our original example, there are two possible plans for feeding Alma. But what ifinstead we are planning forthe cannibalPaxton Fettel?Neither of these plansthat satisfiedAlma’s hungerwill satisfy someone who only eats human flesh!We need a newEatHumanaction to satisfy Fettel.Nowwe have three possible plans to satisfy hunger, but only two aresuitable for Alma, and one is suitable for Paxton Fettel.
在某个时候的世界状况可能反映出我们拥有硬币,钥匙和武器。回到我们最初的示例,有两个可能的喂饱阿尔玛的计划。 但是如果我们打算为食人族的帕克斯顿·费特尔进行规划呢?这些喂饱阿尔玛的计划都不能满足只吃人类肉的人!我们需要一项新的EatHuman Action来满足费特尔。现在我们有三种可能的规划来满足饥饿,但是只有前两项规划适合阿尔玛。 后一项适用于费特尔。
This is basically what we didforF.E.A.R., but instead of planning ways to satisfy hunger,wewere planning ways of eliminating threats. We can satisfy the goal of eliminating a threat byfiring a gun at the threat, but the gun needs to be loaded, or we can use a melee attack, but wehave to move close enough.Sowe’ve seenanother way to implement behaviors that wecould have already implemented with an FSM.So what’s the point?It is easiest tounderstand the benefits of the planning solution by looking at a case study of how these
techniques were applied tothe workflow of modeling character behavior forF.E.A.R.
我们可以不规划消除饥饿的方法,只规划了消除威胁的方法。我们可以通过向威胁开枪来达到消除威胁的目标,但是需要把手枪上膛,或者我们可以使用近战攻击,但是我们必须移动得足够近。因此,我们已经看到了实现行为的另一种方法可以使用FSM实现,所以重点是通过案例研究来了解规划解决方案的好处,并且理解我们是如何把这些的技术应用于架构FEAR的角色行为工作流中的。
案例学习:在FEAR中应用规划系统
The design philosophy at Monolith is that the designer’s job is to create interesting spaces forcombat, packed with opportunities for the A.I.to exploit. For example, spaces filled withfurniture for cover, glass windowsto dive through, and multiple entries for flanking.Designersare not responsible for scripting the behavior of individuals, other than for story elements. Thismeans that the A.I.need to autonomously use the environment to satisfy their goals.
Monolith的设计理念是,设计师的工作是为战斗创造有趣的场地,并为AI开发提供机会。例如,充满家具的空间用于遮盖,可以透过的玻璃窗以及用于侧面切入的入口。除故事元素外,设计师不负责编写AI行为。这意味着AI需要自动根据环境实现其目标。
If we simply drop an A.I.into the worldinWorldEdit (ourleveleditor),start up the gameand lethim see theplayer, the A.I.will do…. nothing. This is because we have not yet given him anygoals.Weneed toassign aGoal Setto each A.I. in WorldEdit. These goals compete foractivation, and the A.I. uses the planner to try to satisfy the highest prioritygoal.
如果我们简单地将AI放到WorldEdit(我们的编辑器)的世界中,启动游戏并让他看到玩家,则AI会…什么也不做。这是因为我们尚未给他任何目标。我们为每个AI分配一个目标。在WorldEdit中。这些目标争夺激活权,而AI使用规划者来尝试满足最高优先级的目标。
We create Goal Sets in GDBEdit, our game database editor. For the purposes of illustration,imagine that wecreated a Goal Set namedGDC06which contains only two goals,PatrolandKillEnemy.When we assign this Goal Set to our soldier in WorldEdit and run the game, heno longer ignores the player. Now he patrols through a warehouse until he sees theplayer,atwhich point he starts firing his weapon.
我们在游戏数据编辑器GDBEdit中创建目标集。想象一下我们创建了一个名为GDC06的目标集,其中仅包含两个目标,Patrol和KillEnemy。当我们将此目标集分配给WorldEdit中的士兵并运行游戏时,他不再忽略玩家。现在他在仓库中巡逻,直到看到玩家为止,这时他开始发射武器。
If we place an assassin in the exact same level, with the sameGDC06Goal Set, we getmarkedly different behavior. The assassin satisfies thePatrolandKillEnemygoals in avery different manner from the soldier. The assassin runs cloaked through the warehouse,jumps up and sticks to the wall, and only comes down when he spots theplayer. He thenjumps down from the wall, and lunges atplayer, swinging his fists.
如果我们将刺客放置在具有合GDC06目标集的完全相同的级别中,我们将获得截然不同的行为。刺客与士兵以完全不同的方式满足了Patrol(巡逻)和KillEnemy(杀死敌人)。刺客会躲在仓库中,跳起来并粘在墙上,只有在他发现玩家时才会掉下来。然后他从墙壁上跳下来背刺玩家。
Finally, if we place a rat in the same levelwith theGDC06Goal Set, we once again seedifferent behavior. The rat patrols on the ground like the soldier, but never attempts to attackat all. What we are seeing is that these characters have the same goals, but differentActionSets, used to satisfy the goals.Thesoldier’s Action Set includesactions for firing weapons,while theassassin’s Action Set haslunges andmelee attacks. Therat has no means ofattacking at all, so he fails to formulate anyvalid plan to satisfy theKillEnemygoal, andhefalls back to the lower priorityPatrolgoal.
最后,如果将老鼠与GDC06目标组放置在同优先级上,我们将再次看到不同的行为。老鼠像士兵一样在地面巡逻,但从未尝试过进攻。我们看到的是这些角色具有相同的目标,但用于实现目标的动作集不同。士兵的动作集包括射击武器的动作,而刺客的动作集则具有突袭和近战攻击。老鼠根本没有进攻的手段,因此他没有制定任何有效的计划来满足杀戮敌人的要求,而他又回到了优先级较低的Patrol。

使用规划系统的三个好处
Theprevious case studyillustratesthe first of three benefits of a planning system. The firstbenefit is the ability to decouplegoals andactions, to allow different types of characters tosatisfygoals in different ways.The second benefit of a planning system is facilitation oflayering simple behaviors to produce complex observable behavior. The third benefit is
empowering characters with dynamic problem solving abilities.
先前的案例研究说明了计划系统的三个好处中的第一个:能够使目标和动作解耦,从而允许不同类型的角色以不同的方式达成目标。规划系统的第二个好处是便于将简单的行为组合以产生复杂的行为。 第三个好处是赋予角色动态解决问题的能力。
好处1:解耦目标和行为
In our previous generation of A.I.systems, we ran into the classic A.I.problem of“MimesandMutants.”We developed our last generationA.I.systemsforuse inNo One Lives Forever 2
(NOLF2) andTron2.0.NOLF2has mimes, whileTron2.0has mutants. Our A.I.systemconsisted ofgoals that competed for activation, just like they do inF.E.A.R.However,in theold system, each goal contained an embeddedFSM. There was no way to separate thegoalfrom the plan used tosatisfythatgoal.If we wanted any variation between the behavior of amime and the behavior of a mutant, orbetweenother character types, we had to add branchesto the embedded state machines. Over the course of two years of development, these statemachines become overly complex, bloated, unmanageable, and a risk to the stability of theproject.
在上一代的AI系统中,我们遇到了经典的“Mimes and Mutants”(模仿和突变)问题。我们的AI系统由竞争激烈的目标组成,就像它们在FEAR中所做的一样,但是,在旧系统中,每个目标都包含一个嵌入式FSM。 没有办法从当前满足目标的规划中分离出目标,如果要使模仿体的行为与突变体的行为或其他类型角色类型之间有任何差异,则必须在嵌入式状态机上添加分支。 在两年的发展过程中,这些状态机变得过于复杂,臃肿,难以管理,并给项目的稳定性带来了风险。
For example, we had out of shape policemen inNOLF2who needed to stop and catch theirbreath every few seconds while chasing.Even though only one type of character ever exhibited this behavior, thisstillrequired a branch in the state machine for theChasegoal tocheck if the character was out of breath.With a planning system, we can giveeach charactertheir own Action Set, and in this case only the policemen would have theaction for catchingtheir breath. This unique behavior would not add any unneeded complexity to other characters.
例如,在《光晕2》中,我们有奇形怪状的警察(猜测是丧尸),他们在追赶时每隔几秒钟需要停下来并喘口气,即使只有一种类型的角色曾表现出这种行为,这仍然需要状态机中的一个分支供追逐目标检查该角色是否不正常,有了规划系统,我们就可以给每个角色各自的动作集,在这种情况下,只有警察才有停下来喘气的动作。 这种独特的行为不会给其他角色类型带来任何不必要的复杂性。
The modular nature of goals andactions benefited usonF.E.A.R.when we decided to add anew enemy type late in development. We added flying drones with a minimal amount of effortby combininggoals andactions from characters we already Райский Сад combining theghost’sactions foraerialmovement with thesoldier’sactions for firing weapons and using tacticalpositions, we were able to create a unique new enemy type in a minimal amount of time,without imposing any risk on existing characters.
当我们决定在开发后期添加新的敌人类型时,目标和行动的模块化本质使FEAR受益。我们通过结合已有角色的目标和行为以最少的工作量添加了飞行无人机。通过将鬼魂的空中行为与士兵的行为结合起来用以发射武器并使用战术位置,我们能够以最少的时间创造出独特的新型敌人类型,不会对现有角色造成任何破坏。
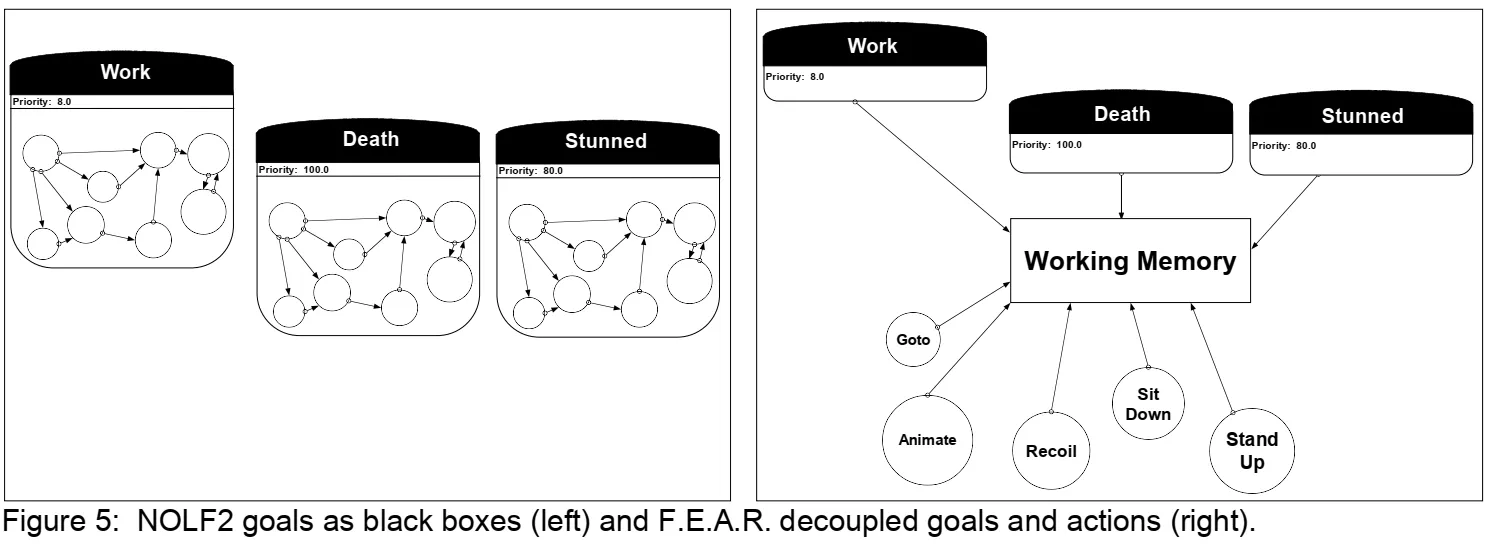
There’sanother good reason for decouplinggoals andactionsas well. In our previous system,goals were self-contained black boxes, and did not share any information with each other.
This can be problematic.CharactersinNOLF2were surrounded byobjectsin the environmentthattheycouldinteract with. For example someonecouldsit down at a desk and do somework.The problem was that only theWorkgoal knew that the A.I.was in a sitting posture,interacting wit the desk. When we shot the A.I., we wanted him to slump naturally over thedesk. Instead, he would finish his work, stand up, push in his chair, and then fall to the floor.This was because there was no information sharing betweengoals, so eachgoal had to exitcleanly, and get the A.I.back into some default statewhere he could cleanly enter the nextgoal.Decoupling thegoals andactions forces them to share information through someexternal working space.In a decoupled system,allgoals andactions have access toinformation including whether the A.I.is sitting or standing, and interacting with a desk or someother object. We can take this knowledge into account when we formulate a plan to satisfy theDeathgoal, and slump over the desk as expected.
还有其他理由也可以将目标和行为解耦。在我们以前的AI系统中,目标是独立的黑盒,并且彼此之间没有共享任何信息。这可能是有问题的。《光晕2》中的角色在它们可能与之交互的环境中被很多对象影响。例如,有人坐在办公桌前做一些工作。问题是只有Work Goal知道AI处于坐姿,与办公桌互动。当我们使用武器击中AI时,我们希望他在桌子上自然滑倒。然而,他会在完成工作后,站起来,推椅子,然后再死在地上。这就是因为目标之间没有信息共享,因此每个目标都必须干净退出,并使AI返回到他可以使用的默认状态,将目标和行为解耦迫使他们通过某个外部工作空间共享信息。在分离的系统中,所有目标和行为都可以访问这个共享信息:包括AI是坐着还是站着,以及与桌子或其他物体进行交互。在制定满足死亡目标的计划时,我们可以考虑这些信息,并按我们希望的那样死在桌子上。
好处2:分层的行为
The second benefit of the planning approach is facilitating the layering of behaviors. You can think of the basic soldier combat behavior in F.E.A.R. as a seven layer dip. We get deep complex tactical behavior by layering a variety of simple atomic behaviors. We wanted the F.E.A.R. A.I. to do everything for a reason. This is in contrast to the NOLF2 A.I., which would run to valid cover and then pop in and out randomly like a shooting gallery. F.E.A.R. A.I.always try to stay covered, never leave cover unless threatened and other cover is available,and fire from cover to the best of their ability
规划方法的第二个好处是促进了行为的分层。 您可以思考FEAR中的基本士兵战斗行为就结合了七层行为。 通过分层各种简单的原子行为,我们获得了深层次的复杂战术行为。 我们想要FEAR AI做某事一定是有因素驱动的。 这与《光晕2》中的AI相反,后者会跑到有效的掩护下,然后像射击场里的靶子一样随机出现。 FEAR的AI始终尝试保持掩护状态,除非有威胁和其他掩护可用,否则不要离开掩护,并尽其所能射击。
We start our seven layer dip with the basics; the beans. A.I. fire their weapons when they detect the player. They can accomplish this with the KillEnemy goal, which they satisfy with
the Attack action.
我们从零开始进行七层浇注。豆子(原文beans,不知道怎么翻译。。)AI检测到玩家时开火。他们可以通过满足他们的KillEnemy目标来实现这一攻击动作。
We want A.I. to value their lives, so next we add the guacamole. The A.I. dodges when a gun is aimed at him. We add a goal and two actions. The Dodge goal can be satisfied with either DodgeShuffle or DodgeRoll.
我们想要AI珍惜他们的生命,所以接下来我们添加一点鳄梨酱(emm,好像是要做糖豆?)。AI在枪对准他时会躲闪。我们添加了一个目标和两个动作。躲闪目标可以通过随机躲闪动作或翻滚躲闪动作来满足。
Next we add the sour cream. When the player gets close enough, A.I. use melee attacks instead of wasting bullets. This behavior requires the addition of only one new AttackMelee action. We already have the KillEnemy goal, which AttackMelee satisfies.
接下来,我们添加酸奶油。当玩家足够接近时,AI使用近战攻击而不是浪费子弹。此行为仅需要添加一个新的AttackMelee操作。这样就有了AttackMelee可以满足的KillEnemy目标。
If A.I. really value their lives, they won’t just dodge, they’ll take cover. This is the salsa! We add the Cover goal. A.I. get themselves to cover with the GotoNode action, at which point the KillEnemy goal takes priority again. A.I. use the AttackFromCover action to satisfy the KillEnemy goal, while they are positioned at a Cover node. We already handled dodging with the guacamole, but now we would like A.I. to dodge in a way that is context-sensitive to taking cover, so we add another action, DodgeCovered.
如果真正珍视自己的生命,AI不会躲避,而是会寻找掩护。这是莎莎酱!(这是什么酱。。。)先添加Cover(掩护)目标,AI进行GoToNode(移动)动作达成Cover目标,然后KillEnemy目标再次获得优先权。AI位于Cover节点时,使用AttackFromCover行为满足KillEnemy目标。我们已经用鳄梨调味酱进行了躲避处理,但是现在我们想让AI能够根据当前情况进行躲避,因此我们添加了另一个动作DodgeCovered(躲避到掩体)。
Dodging is not always enough, so we add the onions; blind firing. If the A.I. gets shot while in cover, he blind fires for a while to make himself harder to hit. This only requires adding one BlindFireFromCover action.
闪避并不总是足够的,所以我们添加洋葱(变咸了。。。)。疯狂扫射。如果是AI在掩护时被射中,他会疯狂扫射一段时间,使自己更难被击中。这仅需要添加一个BlindFireFromCover操作。
The cheese is where things really get exciting. We give the A.I. the ability to reposition when his current cover position is invalidated. This simply requires adding the Ambush goal. When an A.I.’s cover is compromised, he will try to hide at a node designated by designers as an Ambush node. The final layer is the olives, which really bring out the flavor. For this layer, we add dialogue that lets the player know what the A.I. is thinking, and allows the A.I. to communicate with squad members. We’ll discuss this a little later.
奶酪是真正令人兴奋的地方。我们给予AI当他当前的掩护位置无效时的重新定位的能力。这仅需要添加Ambush(伏击)目标。当AI的掩护遭到破坏时,他将尝试隐藏在设计师指定为Ambush节点的节点上。最后一层是橄榄,它能带出真正的风味。对于这一层,我们添加对话,使玩家知道AI正在思考什么,并允许AI与小队成员交流。我们稍后再讨论这一块的内容。
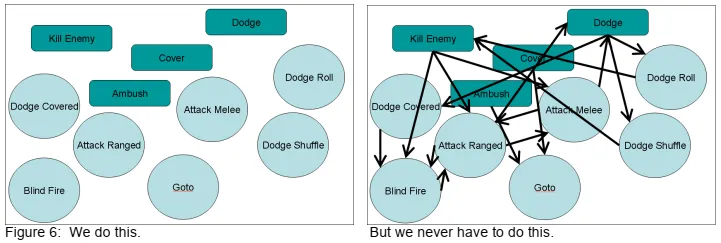
The primary point we are trying to get across here is that with a planning system, we can just toss in goals and actions. We never have to manually specify the transitions between these behaviors. The A.I. figure out the dependencies themselves at run-time based on the goal state and the preconditions and effects of actions
我们试图在这里解决的主要问题是,有了一个规划系统,我们就可以投入目标和行动。我们不必手动指定这些行为之间的过渡。AI根据目标状态以及操作的前提条件和效果,在运行时找出依赖关系本身。
Late in development of NOLF2, we added the requirement that A.I. would turn on lights whenever entering a dark room. In our old system, this required us to revisit the state machine inside every goal and figure out how to insert this behavior. This was both a headache, and a risky thing to do so late in development. With the F.E.A.R. planning system, adding this behavior would have been much easier, as we could have just added a TurnOnLights action with a LightsOn effect, and added a LightsOn precondition to the Goto action. This would affect every goal that was satisfied by using the Goto action.
在《光晕2》开发的后期,我们增加了AI的要求。 AI进入黑暗的房间时都会打开灯。 在我们的旧系统中,这要求我们重新访问每个目标内的状态机,并弄清楚如何插入此行为。 在开发的后期这样做既令人头疼,又是冒险的事情。 在FEAR规划系统中,添加此行为会容易得多,因为我们可以只添加具有LightsOn效果的TurnOnLights动作,并为Goto动作添加LightsOn前提。 这将影响使用Goto操作达到的每个目标。
好处3:动态处理问题
The third benefit of a planning system is the dynamic problem solving ability that re-planning gives the A.I. Imagine a scenario where we have a patrolling A.I. who walks through a door, sees the player, and starts firing. If we run this scenario again, but this time the player physically holds the door shut with his body, we will see the A.I. try to open the door and fail. He then re-plans and decides to kick the door. When this fails, he re-plans again and decides to dive through the window and ends up close enough to use a melee attack!
计划系统的第三个优点是动态规划解决能力,想象一个场景,我们有一个巡逻的AI他走过一扇门,看到了玩家,然后开始射击。如果我们再次运行此场景,但是这次玩家用身体将门顶住,我们将看到AI尝试打开门,然后失败,然后,他重新规划并决定踢门,如果还失败,他会重新计划并决定潜入窗户,最后靠近以进行近战攻击!
This dynamic behavior arises out of re-planning while taking into account knowledge gained through previous failures. In our previous discussion of decoupling goals and actions, we saw how knowledge can be centralized in shared working memory. As the A.I. discovers obstacles that invalidate his plan, such as the blocked door, he can record this knowledge in working memory, and take it into consideration when re-planning to find alternative solutions to the KillEnemy goal.
这种动态行为来自重新计划,同时考虑了先前失败中获得的信息。在先前关于解耦目标和动作的讨论中,我们看到了如何将信息集中在共享的工作记忆中。作为AI发现使他的计划无效的障碍,例如被封锁的门,他可以将这些知识记录在工作记忆中,并在重新计划时将其考虑在内,以找到实现KillEnemy目标的替代解决方案。
FEAR规划和STRIPS规划之间的差异
Now that we have seen the benefits of driving character behavior with a planning system, we will discuss how our system differs from STRIPS. We refer to our planning system as GoalOriented Action Planning (GOAP), as it was inspired by discussions in the GOAP working group of the A.I. Interface Standards Committee [AIISC]. We made several changes in order to make the planning system practical for a real-time game. These changes make the planner more efficient and controllable, while preserving the benefits previously described. Our system differs from STRIPS in four ways. We added a cost per action, eliminated Add and Delete Lists for effects, and added procedural preconditions and effects [Orkin 2005, Orkin 2004,Orkin 2003]. The underlying agent architecture that supports planning was inspired by C4 from the M.I.T. Media Lab’s Synthetic Characters group, described in their 2001 GDC paper [Burke, Isla, Downie, Ivanov & Blumberg 2001], and is further detailed in [Orkin 2005]
现在,我们已经看到了使用规划系统驱动角色行为的好处,我们将讨论我们的系统与STRIPS的不同之处。 我们将我们的计划系统称为目标导向的行动计划(GOAP),为了使计划系统适用于实时游戏,我们进行了一些更改。 这些更改使规划者更加有效和可控,同时保留了先前描述的好处。我们的系统在四个方面与STRIPS不同。 我们为每项操作增加了权重值,消除了效果的添加和删除列表,并增加了程序前提条件和效果。
区别1:每个行为的权重
Earlier we said that if Alma has both the phone number and the recipe, either plan is valid to satisfy her hunger. If we assign a cost per action, we can force Alma to prefer one action over another. For example we assign the OrderPizza action a cost of 2.0, and the BakePie action a cost of 8.0. If she cannot satisfy the preconditions of ordering pizza, she can fall back to baking a pie.
之前我们说过,如果阿尔玛既有电话号码又有食谱,那么任何一个计划都可以满足她的饥饿感。如果我们为每个动作分配权重,我们可以强迫Alma优先选择一个动作而不是另一个。例如,我们将OrderPizza操作的权重指定为2.0,将BakePie操作的权重指定为8.0。如果她不能满足订购披萨的先决条件,则可以退后一步来烤馅饼。
This is where our old friend A* comes in! Now that we have a cost metric, we can use this cost to guide our A* search toward the lowest cost sequence of actions to satisfy some goal. Normally we think of A* as a means of finding a navigational path, and we use it in this way in F.E.A.R. too, to find paths through the navigational mesh. The fact is, however, that A* is really a general search algorithm. A* can be used to search for the shortest path through any graph of nodes connects by edges. In the case of navigation, it is intuitive to think of navigational mesh polygons as nodes, and the edges of the polygons as edges in the graph that connect that connect one node to another. In the case of planning, the nodes are states of the world, and we are searching to find a path to the goal state. The edges connecting different states of the world are the actions that lead the state of the world to change from one to another. So, we use A* for both navigation and planning in F.E.A.R., and in each case we search through entirely different data structures. However, there are situations where we use both. For example, when an A.I. crawls under an obstacle, we first search for a navigational path, and then search for a plan that will allow the A.I. to overcome the obstacle on that path
现在我们有了权重指标,我们可以使用此指标来指导我们的A*搜索朝着成本最低的动作序列迈进,以实现某些目标。通常,我们将A*视为查找导航路径的一种方式,并且在FEAR中以这种方式使用它。也可以找到通过导航网格的路径。但是事实是,A*实际上是一种通用的搜索算法。 A *可用于搜索通过边连接的任何节点图的最短路径。在导航的情况下,直观地将导航网格多边形视为节点,而将多边形的边缘视为将一个节点连接到另一个节点的连接图中的边缘。在规划的情况下,节点是世界的状态,我们正在寻找路径以达到目标状态。连接世界不同状态的边缘是导致世界状态从一种变化到另一种的行为。因此,我们在FEAR中使用A*进行导航和规划,并且在每种情况下我们都搜索完全不同的数据结构。但是,在某些情况下我们会同时使用两者。例如,当一个AI爬到障碍物下面,我们首先搜索导航路径,然后搜索规划让AI克服那条道路上的障碍。(可能表述的不是特别清晰,这里的意思是我们通常把A*算法用在人物寻路和寻找可达成目标的规划的最短路径上这两种方案)
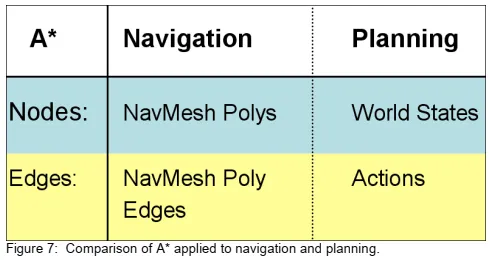
区别2:没有增加/删除列表
Our next modification to STRIPS is eliminating the Add and Delete Lists when specifying effects of actions. Instead of representing effects the way we described earlier with Add and Delete Lists, we chose to represent both preconditions and effects with a fixed-sized array representing the world state. This makes it trivial to find the action that will have an effect that satisfies some goal or precondition. For example, the Attack action has the precondition that our weapon is loaded, and the Reload action has the effect that the weapon is loaded. It is easy to see that these actions can chain.
我们对STRIPS的下一个修改是在指定动作效果时消除了添加和删除列表。 我们选择使用固定大小的数组表示世界状态,而不是像我们之前使用“添加和删除列表”描述效果那样来表示先决条件和效果。 这使得找到具有满足某些目标或前提条件的效果的动作变得微不足道(这里应该指数组遍历查找效率高)。 例如,“攻击”动作具有先加载我们的武器的前提,而“重新加载”动作具有先加载武器的效果。 显而易见,这些动作可以连锁。(个人感觉这里用带键值对的散列表更好一些)
Our world state consists of an array of four-byte values. Here are a few examples of the type of variables we store。
我们的世界状态由四字节值组成的数组。 以下是一些我们存储的变量类型的示例
bool TargetDead
bool WeaponLoaded
enum OnVehicleType
AtNode [HANDLE] –or- [variable*]
The two versions of the AtNode variable indicate that some variables may have a constant or variable value. A variable value is a pointer to the value in the parent goal or action’s precondition world state array. For instance, the Goto action can satisfy the Cover goal, allowing the A.I. to arrive at the desired cover node. The Cover goal specifies which node to Goto in the array representing the goal world state.
AtNode变量的两个版本指示某些变量可能具有常数或变量值。变量值是指向父目标或动作的前提世界状态数组中的值的指针。例如,Goto动作可以满足Cover目标,从而允许AI到达所需的掩体地点。Cover目标指定代表目标世界状态的数组中要转到的节点。
The fixed sized array does limit us though. While an A.I. may have multiple weapons, and multiple targets, he can only reason about one of each during planning, because the world state array has only one slot for each. We use attention-selection sub-systems outside of the planner to deal with this. Targeting and weapon systems choose which weapon and enemy are currently in focus, and the planner only needs to concern itself with them
固定大小的数组确实限制了我们。 AI可能拥有多种武器和多个目标,因此在计划期间他只能计算其中一种武器,因为世界状态阵列每种武器只有一个插槽。 我们使用规划程序外部的注意选择子系统来处理此问题。瞄准和武器系统选择当前注意力集中的武器和敌人,而计划者只需关心它们就好了。
区别3:程序化的先决条件
It’s not practical to represent everything we need to know about the entire game world in our fixed-sized array of variables, so we added the ability to run additional procedural precondition checks. For F.E.A.R. an action is a C++ class that has the preconditions both represented as an array of world state variables, and as a function that can do additional filtering. An A.I. trying to escape danger will run away if he can find a path to safety, or hunker down in place if he can’t find anywhere to go. The run away action is preferable, but can only be used if the CheckProceduralPreconditions() function return true after searching for a safe path through the NavMesh. It would be impractical to always keep track of whether an escape path exists in our world state, because pathfinding is expensive. The procedural precondition function allows us to do checks like this on-demand only when necessary.
在固定大小的变量数组中表示我们需要了解的整个游戏世界的所有内容不切实际,因此我们增加了运行其他程序前提条件检查的功能。 对于FEAR一个动作是一个C++类,其前提条件既表示为世界状态变量的数组,又表示为可以进行附加过滤的函数。一个AI尝试逃避危险,如果能找到通往安全的道路,就试图逃避;如果他找不到任何可以去的地方,则试图死战到底。 最好使用“逃跑”操作,但仅当CheckProceduralPreconditions()函数在通过NavMesh搜索安全路径后返回true时才能使用。始终跟踪在我们的世界状态下是否存在逃生路径是不切实际的,因为寻路成本很高。程序前提条件功能使我们仅在必要时才按需执行此类检查。
区别4:程序化的效果
Similar to procedural preconditions, our final difference from STRIPS is the addition of procedural effects. We don’t want to simply directly apply the effects that we’ve represented as world state variables, because that would indicate that changes are instantaneous. In reality it takes some amount of time to move to a destination, or eliminate a threat. This is where the planning system connects to the FSM. When we execute our plan, we sequentially activate our actions, which in turn set the current state, and any associated parameters.The code inside of the ActivateAction() function sets the A.I. into some state, and sets some parameters. For example, the Flee action sets the A.I. into the Goto state, and sets some specific destination to run to. Our C++ class for an action looks something like this:
与程序前提条件类似,我们与STRIPS的最终区别是增加了程序效果。 我们不想简单地直接应用我们表示为世界状态变量的效果,因为那将表明更改是瞬时的。 实际上,移至目的地或消除威胁要花费一些时间。这是也是规划系统与FSM的相关联的地方。执行规划划时,我们会依次激活我们的动作,依次设置当前状态和所有相关参数ActivateAction()函数内部的代码设置了AI。 进入某种状态,并设置一些参数。例如,“逃跑”动作可设置AI进入“GoTo”状态,并设置目的地点坐标。 我们用于动作的C++类看起来像这样:
1 | class Action |
群组行为
Now that we have A.I. that are smart enough to take care of the basics themselves, the A.I. programmer and designers can focus their energy on squad behaviors. We have a global coordinator in F.E.A.R. that periodically re-clusters A.I. into squads based on proximity. At any point in time, each of these squads may execute zero or one squad behaviors. Squad behaviors fall into two categories, simple and complex behaviors. Simple behaviors involve laying suppression fire, sending A.I. to different positions, or A.I. following each other. Complex behaviors handle things that require more detailed analysis of the situation, like flanking, coordinated strikes, retreats, and calling for and integrating reinforcements.
现在AI聪明到生活可以自理的程度了,程序员和设计师可以将精力集中在群组的行为上。 我们在FEAR有一个全局协调员(下面可能会以班长的身份出现)。定期重新编排AI根据邻近程度划分为小队。 在任何时间点,这些小队中的每一个小队都可以执行零或一个小队行为。小队的行为分为两类,简单行为和复杂行为。 简单的行为包括火力压制,让AI到不同的位置,或AI彼此跟随。复杂的行为会处理需要对情况进行更详细分析的事情,例如侧翼,协调一致的撤退以及要求和整合增援部队。
简单群组行为
We have four simple behaviors. Get-to-Cover gets all squad members who are not currently in valid cover into valid cover, while one squad member lays suppression fire. Advance-Cover moves members of a squad to valid cover closer to a threat, while one squad member lays suppression fire. Orderly-Advance moves a squad to some position in a single file line, where each A.I. covers the one in front, and the last A.I. faces backwards to cover from behind. Search splits the squad into pairs who cover each other as they systematically search rooms in some area.
我们有四种简单的行为。 Get-to-Cover将当前不在有效掩护下的所有小队成员都转换为有效掩护,而一名小队成员则进行火力压制。 推进掩护将群组成员移动到更接近威胁的有效掩护处,而一个班组成员则进行抑制射击。有序推进将小队移动到单个行阵中,每个AI掩护了前面的一个,最后一个AI面朝后从后面掩护。搜索将小队分成几对,当他们系统地搜索某个区域的房间时,他们会互相掩护。
Simple squad behaviors follow four steps. First the squad behavior tries to find A.I. that can fill required slots. If it finds participants, the squad behavior activates and sends orders to squad members. A.I. have goals to respond to orders, and it is up to the A.I. to prioritize following those orders versus satisfying other goals. For example, fleeing from danger may trump following an order to advance. The behavior then monitors the progress of the A.I. each clock tick. Eventually either the A.I. fulfill the orders, or fail due to death or another interruption.
简单的群体行为遵循四个步骤。 首先,小队的行为试图找到AI可以填充所需的插槽。如果找到参与者,则小队行为将激活并将命令发送给小队成员,AI响应请求的目标,这取决于AI是否优先遵循这些命令而不是满足其他目标。 例如,AI收到前进命令但是他认为逃避危险比前进更加重要他就会执行逃避危险而不是前景命令。然后,该行为将每帧监视AI的进度,最终要么是AI履行命令,或者由于死亡或其他干扰而失败。
Let’s look at the Get-to-Cover squad behavior as an example. Say we have a couple A.I.firing at the player from cover. If the player fires at one A.I. and invalidates his cover, the squad behavior can now activate. That is, it can find participants to fill the slots of one A.I.laying suppression fire, and one or more A.I. in need of valid cover, who have valid cover to go to. Note that the squad behavior does not need to analyze the map and determine where there is available cover. This is because each A.I. already has sensors keeping an up to date list of potentially valid cover positions nearby. All the squad behavior needs to do is select one node that the A.I. knows about, and ensure that other A.I. are not ordered to go to the same node. Once a node has been selected, the squad behavior sends orders to one A.I. to suppress, and orders the others to move to the valid cover positions. The A.I. re-evaluate their goals, and decide the highest priority goal is to begin following the orders. The squad behavior monitors their progress. If all A.I. fulfill their orders, and the repositioning A.I. has made it to a valid cover position, the squad behavior has succeeded. On the other hand, if the player throws a grenade, and invalidates the new cover position, the A.I. may re-evaluate his goals and decide it’s a higher priority to flee than to follow orders. In this case, the A.I. flees and ends up somewhere unexpected, so the squad behavior fails。
让我们以“寻找掩护”小队的行为为例。假设一对AI从掩体向玩家开火了,如果玩家向其中一个AI开火并使他的掩护无效,小队的行为现在可以激活。也就是说,它可以找到参与者来填补这个AI的位置进行火力压制,然后一个或多个AI(可以找到掩体的那些AI)需要掩体。请注意,小队的行为不需要分析地图并确定哪里有可用的掩护。这是因为每个AI已经有传感器保留附近可能有效的掩护位置的最新列表。群体行为所需要做的就是选择一个AI知道并确保其他AI不被命令去同一个节点。一旦选择了一个节点,小队的行为就会向一个AI发送命令。相应的命令其他人转移到有效的掩护位置。AI重新评估他们的目标,并确定最高优先级的目标然后开始遵循命令。小队的行为监视着他们的进度。如果全部是AI完成他们的订单,并重新定位AI已将其设置为有效的掩护位置,则小队的行为已成功。另一方面,如果玩家投掷手榴弹并使新的掩护位置无效,则AI可能会重新评估他的目标,并决定逃跑的优先级高于服从命令。在这种情况下逃跑造成的结果是出乎意料的,因此班长的行为失败了。
复杂群组行为
Now let’s look at our complex behaviors. The truth is, we actually did not have any complex squad behaviors at all in F.E.A.R. Dynamic situations emerge out of the interplay between the squad level decision making, and the individual A.I.’s decision making, and often create the illusion of more complex squad behavior than what actually exists!
现在,让我们看看我们的复杂行为。事实上,在FEAR中我们实际上根本没有任何复杂的群组行为。动态情况是由群组决策与个人AI决策之间的相互作用产生的,常常使人产生比实际情况更复杂的群组行为的错觉!
Imagine we have a situation similar to what we saw earlier, where the player has invalidated one of the A.I.’s cover positions, and a squad behavior orders the A.I. to move to the valid cover position. If there is some obstacle in the level, like a solid wall, the A.I. may take a back route and resurface on the player’s side. It appears that the A.I. is flanking, but in fact this is just a side effect of moving to the only available valid cover he is aware of.
想象一下,我们遇到的情况类似于我们之前看到的情况,即玩家使AI的掩护位置之一无效,并且班长的行为命令了AI。移动到有效的掩体位置。如果地图中有障碍物,例如坚固的墙壁,则AI可能会向后走,并重新暴露在玩家视野里。看来AI是侧翼突袭,但实际上这只是转移到他所知道的唯一可用有效掩护的副作用而已(XD)。
In another scenario, maybe the A.I.s’ cover positions are still valid, but there is cover available closer to the player, so the Advance-Cover squad behavior activates and each A.I. moves up to the next available valid cover that is nearer to the threat. If there are walls or obstacles between the A.I. and the player, their route to cover may lead them to come at the player from the sides. It appears as though they are executing some kind of coordinated pincher attack, when really they are just moving to nearer cover that happens to be on either side of the player. Retreats emerge in a similar manner
在另一种情况下,也许AI们的掩护位置仍然有效,但是在靠近玩家的地方有可用的掩护,因此激活了Advance-Cover小队的行为,并且每个AI移至下一个更接近威胁的可用有效保护范围。 AI之间是否有墙壁或障碍物并且玩家的掩护路线可能会导致他们从侧面突袭玩家。看来他们正在执行某种形式的协同式钳夹攻击,而实际上,他们只是在移动到恰好位于球员两侧的较近掩护。撤退有时候也会出现这种情况。
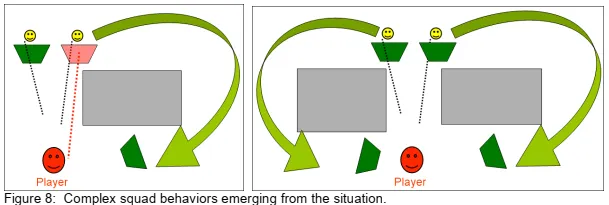
群组行为实现
The design of our squad behavior system was inspired by Evans’ and Barnet’s 2002 GDC paper, “Social Activities: Implementing Wittgenstein” [Evans & Barnet 2002]. Our actual implementation of squad behaviors was not anything particularly formal. We only used the formalized STRIPS-like planning system for behavior of individual characters, and implemented something more ad-hoc for our squad behaviors. It is the separation between planning for individuals and planning for squads that is more important than any specific implementation.
我们群体行为系统的设计受到Evans和Barnet的2002 GDC的启发论文“Social Activities: Implementing Wittgenstein” 。我们实际实施小队行为并不是特别正式的事情。我们只使用了正式的类似STRIPS的规划系统,用于单个角色的行为,以及为我们的小队行为实施了一些临时性的措施。为个人做规划和为小队做规划的分离比任何具体规划实现都重要。
A logical next step from what we did for F.E.A.R. would be to apply a formalized planning system to the squad behaviors. A developer interested in planning for squads may want to look at Hierarchical Task Network planning (HTN), which facilitates planning actions that occur in parallel better than STRIPS planning [Russell & Norvig 2002]. Planning for a squad of A.I. will require planning multiple actions that run in parallel. HTN planning techniques have been successfully applied to the coordination of Unreal Tournament bots [Muñoz-Avila & Hoang 2006, Hoang, Lee-Urban, & Muñoz-Avila 2005, Muñoz-Avila & Fisher 2004]
按理来说,下一步我们应该为FEAR设计一个正式的群组规划行为。对规划群组有兴趣的开发人员可能想要看一下分层任务网络计划(HTN),它有助于规划发生的动作比STRIPS规划要更好[Russell&Norvig 2002]。规划一支AI小组
将需要计划多个并行运行的动作。 HTN规划技术已经成功地应用于虚幻竞技场机器人的协调[Muñoz-Avila&Hoang2006年,Hoang,Lee-Urban和&Muñoz-Avila,2005年,Muñoz-Avila和Fisher 2004年]
群组交流
There is no point in spending time and effort implementing squad behaviors if in the end the coordination of the A.I. is not apparent to the player. The squad behavior layer gives us an opportunity to look at the current situation from a bird’s eye view, where we can see everyone at once, and find some corresponding dialogue sequence. Having A.I. speak to each other allows us to cue the player in to the fact that the coordination is intentional.
如果最终AI协调工作对于玩家来说不可见的话,那么花时间和精力实施小队行为毫无意义。群组行为层使我们有机会从鸟瞰的角度看待当前情况,我们可以立即看到每个人,并找到一些相应的对话顺序。AI相互交谈使我们可以提示玩家该协调是有预谋的。
Vocalizing intentions can sometimes even be enough, without any actual implementation of the associated squad behavior. For example, in F.E.A.R. when an A.I. realizes that he is the last surviving member of a squad, he says some variation of “I need reinforcements.” We did not really implement any mechanism for the A.I. to bring in reinforcements, but as the player progresses through the level, he is sure to see more enemy A.I. soon enough. The player’s assumption is that the next A.I. encountered are the reinforcements called in by the previously speaking A.I., when in reality this is not the case.
发声意图有时就很足够了,而无需实际执行相关的群组行为。例如,在FEAR当一个人工智能他意识到自己是该队最后一个幸存的成员,他说“我需要增援”。我们实际上没有为AI执行任何机制。进行增援,但随着玩家逐步升级,他肯定很快就会看到更多敌人。玩家的认为下一个遇到的是先前讲过的AI要求的增援,但实际上并非如此。
总结
Real-time planning empowers A.I. characters with the ability to reason. Think of the difference between predefining state transitions and planning in real-time as analogous to the difference between pre-rendered and real-time rendered graphics. If we render in real-time, we can simulate the affects of lighting and perspective, and bring the gaming experience that much closer to reality. The same can be said of planning. By planning in real-time, we can simulate the affect of various factors on reasoning, and adapt behavior to correspond. With F.E.A.R., we demonstrated that planning in real-time is a practical solution for the current generation of games. Moving forward, planning looks to be a promising solution for modeling group and social behaviors, increasing characters’ command of language, and designing cooperative characters
实时计划可增强AI的推理能力。思考一下预定义状态转换和实时规划的差别就像是预先渲染(烘焙技术?)和实时渲染的差别。 如果我们进行实时渲染,我们可以模拟照明和透视的影响,并使游戏体验更加接近现实。实时规划也是一个道理。 通过实时计划,我们可以模拟各种因素对推理的影响,并使行为适应相应的行为。 通过FEAR,我们证明了实时规划是当前一代游戏的实用解决方案。 展望未来,规划似乎是一种有前途的解决方案,可用于架构群体和社交行为,增加角色的语言控制能力以及更加合理的设计合作角色。
 微信
微信 支付宝
支付宝



