ET篇:ETBook笔记汇总
1.2 为什么使用C# .net core做服务端?
GitHub原地址:
黑体字为作者(熊猫大佬)原创,红色为个人理解
游戏服务端从早期的单服到分布式,开发越来越复杂,对稳定性,开发效率要求越来越高。开发语言的选择也逐步发生了变化,C 到 C++ 到 C++ + PYTHON 或者C++ + LUA 到现在 很多公司开始使用erlang,go,java,c#。目前是一个百花齐放的局面。
但是如果是要你重新做一个网游server,不考虑对公司或者已有的东西兼容性,你会怎么选择?我仔细想了一下这个问题,大概有这个几个方面需要考虑:
1. 语言的稳定性(致命性)
游戏服务器的特点是高负载低延时。所以一般服务端进程都是带状态的,一旦挂掉就意味着数据丢失,这点是无法容忍的。
2. 运行时热更(致命性)
游戏服务器逻辑极其复杂,很容易出现bug,但是又不能经常停服,所以热更修复bug就显得十分必要。出现错误开发人员可以立即编写代码,然后热更修复,线上用户完全感觉不到。
3. 是否有协程支持(重要性5星)
分布式服务器架构,进程与进程之间必然会有大量交互。由于游戏逻辑很难拆分成多线程,所以一般来说都是逻辑单线程。如果没有协程支持,必然产生大量回调,代码维护会变得非常困难。
4. 编译速度(重要性5星)
使用c++开发,30%的时间都浪费在编译上。假如编译很快或者不需要编译,必定大大提高开发效率。
5. 跨平台(4星)
一般游戏服务器都架设在linux上面。但是平常开发,使用windows会更加方便,如果跨平台,开发以及测试效率会大大提升,并且不需要单独搞一个开发机,本机电脑就可以满足平常开发
6. 可阅读性,可重构性(3星)
代码可以重构能大大减轻写代码的难度
7. 库是否齐全,生态是否完善(3星)
库齐全,生态好,自己需要造的轮子就少
8.跟客户端统一语言(3星)
客户端服务端共用语言,优势十分明显,很多代码可以复用,逻辑程序员不再需要区分前后端,双端都可以写,一个人即可完成一个功能,大大减少了沟通的时间成本。
9. IDE的支持(3星)
代码提示,重构等支持,优秀的IDE能提高几倍的开发效率。
10. 语言的性能(1星)
目前服务器性能都不是太大问题,不过性能好总比性能差要强。
| 语言 | C# | C/C++ | Java | Go | Lua | Python | Erlang |
|---|---|---|---|---|---|---|---|
| 稳定性 | 稳定 | 容易挂 | 稳定 | 稳定 | 稳定 | 稳定 | 稳定 |
| 运行时热更 | 支持 | 较难支持 | 支持 | 不支持 | 支持 | 支持 | 支持 |
| 跨平台 | 支持 | 较难支持 | 支持 | 支持 | 较难支持 | 支持 | 支持 |
| 协程 | 有 | 需要自己实现 | 支持不好 | 支持 | 支持 | 支持 | 支持 |
| 编译速度 | 快 | 慢 | 快 | 快 | 不需要编译 | 不需要编译 | 不需要编译 |
| 阅读性重构性 | 好 | 一般 | 好 | 一般 | 差 | 差 | 差 |
| 游戏库跟生态 | 好 | 好 | 一般 | 一般 | 差 | 好 | 一般 |
| 客户端统一语言 | Unity | Unity、UE4 | 暂无 | 暂无 | Unity、UE4 | UE4 | 暂无 |
| IDE的支持 | 好 | 好 | 好 | 普通 | 差 | 差 | 差 |
| 语言的性能 | 好 | 极好 | 好 | 好 | 差 | 很差 | 差 |
从表格可以看出:
- C/C++稳定性差,编译速度慢,存在致命缺陷
- Go不支持热更,由于不支持泛型,重构性较差,无法跟客户端共享代码,存在致命缺陷
- Java协程支持差,无法跟客户端共享代码
- Lua库少,性能差,代码可阅读性可重构性差,跨平台完全依赖C/C++,处理起来麻烦,ide支持差
- Python 性能很差,代码可阅读性可重构性差,无法跟客户端共享代码,ide支持差
- Erlang 性能差,函数式风格不好上手,ide支持差
- C# .net core各个方便都非常优秀,不过跟UE4无法共享代码 当前Unity是最火的游戏引擎,C#服务端搭配Unity完全是天作之合,基本上找不到缺陷。
2.1 什么是协程
GitHub原地址:
黑体字为作者(熊猫大佬)原创,红色为个人理解
说到协程,我们先了解什么是异步,异步简单说来就是,我要发起一个调用,但是这个被调用方(可能是其它线程,也可能是IO)出结果需要一段时间,我不想让这个调用阻塞住调用方的整个线程,因此传给被调用方一个回调函数,被调用方运行完成后回调这个回调函数就能通知调用方继续往下执行。举个例子:
下面的代码,主线程一直循环,每循环一次sleep 1毫秒,计数加一,每10000次打印一次。
1 | private static void Main() |
这时我需要加个功能,在程序一开始,我希望在5秒钟之后打印出loopCount的值。看到5秒后我们可以想到Sleep方法,它会阻塞线程一定时间然后继续执行。我们显然不能在主线程中Sleep,因为会破坏掉每10000次计数打印一次的逻辑。
1 | // example2_1 |
我们在这里设计了一个WaitTimeAsync方法,WaitTimeAsync其实就是一个典型的异步方法,它从主线程发起调用,传入了一个WaitTimeFinishCallback回调方法做参数,开启了一个线程,线程Sleep一定时间后,将传过来的回调扔回到主线程执行。OneThreadSynchronizationContext是一个跨线程队列,任何线程可以往里面扔委托,OneThreadSynchronizationContext的Update方法在主线程中调用,会将这些委托取出来放到主线程执行。为什么回调方法需要扔回到主线程执行呢?因为回调方法中读取了loopCount,loopCount在主线程中也有读写,所以要么加锁,要么永远保证只在主线程中读写。加锁是个不好的做法,代码中到处是锁会导致阅读跟维护困难,很容易产生多线程bug。这中将逻辑打包成委托然后扔回另外一个线程多线程开发中常用的技巧。
我们可能又有个新需求,WaitTimeFinishCallback执行完成之后,再想等3秒,再打印一下loopCount。
1 | private static void WaitTimeAsync(int waitTime, Action action) |
我们这时还可能改需求,需要在程序启动5秒后,接下来4秒,再接下来3秒,打印loopCount,也就是上面的逻辑中间再插入一个3秒等待。
1 | private static void WaitTimeAsync(int waitTime, Action action) |
这样中间插入一段代码,显得非常麻烦。这里可以回答什么是协程了,其实这一串串回调就是协程。
运行结果

以下是我个人理解与笔记
先来看OneThreadSynchronizationContext类,他继承了SynchronizationContext类,而SyncehronizationContext是干嘛的呢?
SynchronizationContext提供在各种同步模型中传播同步上下文的基本功能。
而对于OneThreadSynchronizationContext,我的理解就是,收集各个线程的回调方法,并且放到主线程进行。具体为何熊猫在上面已说明。
1 | using System; |
我们注意到,在代码的最后一行,有一个()=>符号,这是兰布达表达式,它实质上是声明了一个不含参的委托,后面的callback(state)是它内部的的具体方法。
那么Post的具体作用就是,如果当前入队的线程是主线程,就直接执行其回调方法,否则就将其入队,在Update轮询。
我们回到主程序
在第一步执行WaitTimeAsync,并将WaitTimeFinishCallback注册为回调方法,在第二步里面,我们又看到了()=>符号,在这里是什么意思呢
我们先来看Thread
所以我们知道,WaitTime被封装成了委托,他将在Thread.Start();的时候执行,至此,本篇笔记到此结束,如果还不懂,请大家自己好好琢磨。
2.2 更好的协程
GitHub原地址:
黑体字为作者(熊猫大佬)原创,红色为个人理解
上文讲了一串回调就是协程,显然这样写代码,增加逻辑,插入逻辑非常容易出错。我们需要利用异步语法把这个异步回调的形式改成同步的形式,幸好C#已经帮我们设计好了,看代码
1 | // example2_2 |
在这段代码里面,WaitTimeAsync方法中,我们利用了TaskCompletionSource类替代了之前传入的Action参数,WaitTimeAsync方法返回了一个Task类型的结果。WaitTime中我们把action()替换成了tcs.SetResult(true),WaitTimeAsync方法前使用await关键字,这样可以将一连串的回调改成同步的形式。这样一来代码显得十分简洁,开发起来也方便多了。
这里还有个技巧,我们发现WaitTime中需要将tcs.SetResult扔回到主线程执行,微软给我们提供了一种简单的方法,参考example2_2_2,在主线程设置好同步上下文,
1 | // example2_2_2 |
在WaitTime中直接调用tcs.SetResult(true)就行了,回调会自动扔到同步上下文中,而同步上下文我们可以在主线程中取出回调执行,这样自动能够完成回到主线程的操作
1 | private static void WaitTime(int waitTime, TaskCompletionSource<bool> tcs) |
如果不设置同步上下文,你会发现打印出来当前线程就不是主线程了,这也是很多第三方库跟.net core内置库的用法,默认不回调到主线程,所以我们使用的时候需要设置下同步上下文。其实这个设计本人觉得没有必要,交由库的开发者去实现更好,尤其是在游戏开发中,逻辑全部是单线程的,回调每次都走一遍同步上下文就显得多余了,所以ET框架提供了不使用同步上下文的实现ETTask,代码更加简洁更加高效,这个后面会讲到。
运行结果
以下是我个人理解与笔记
这一次的代码比上一次简洁不少,但是理解起来的难度却大了不少,主要是因为出现了几个陌生的面孔
- async
- await
- Task
- TaskCompletionSource
async和await
async/await 结构可分成两部分:
- **async:就是在方法前面加上async修饰符,调用的话和调用普通函数没区别。**该方法异步执行工作,然后立刻返回到调用方法;
- await 表达式:用于异步方法内部,指出需要异步执行的任务。一个异步方法可以包含多个 await 表达式(不存在 await 表达式的话 IDE 会发出警告),注意,await方法是阻塞的,当前的await如果没有完成(返回结果),将不会执行下面的代码
Task
个人理解和Thread关系就是青出于蓝而胜于蓝(虽然不太恰当,因为他最终还是依赖于Thread运行)
Task和Thread的区别
TaskCompletionSource
个人理解是对于Task状态以及相关资源的封装
整体程序理解(不代表程序实际运行顺序)
async Crontine()——WaitTimeAsync(int waitTime)——Thread thread = new Thread(()=>WaitTime(waitTime, tcs)); thread.Start();——tcs.SetResult(true)(此时当前Task执行完毕,即tcs.SetResult代表当前Task已经结束,开始回到async Crontine函数,运行下一个await,执行下一个Task)
2.3 单线程异步
GitHub原文地址:
黑体字为作者(熊猫大佬)原创,红色为个人理解
前面几个例子都是多线程实现的异步,但是异步显然不仅仅是多线程的。我们在之前的例子中使用了Sleep来实现时间的等待,每一个计时器都需要使用一个线程,会导致线程切换频繁,这个实现效率很低,平常是不会这样做的。一般游戏逻辑中会设计一个单线程的计时器,我们这里做一个简单的实现,用来讲解单线程异步。
1 | // example2_3 |
这个例子同样实现了一个简单的计时方法,WaitTimeAsync调用时会将回调方法跟时间记录下来,主线程每帧都会调用CheckTimerOut,CheckTimerOut里面判断计时器是否过期,过期了则调用回调方法。整个逻辑都在主线程中完成,同样是异步方法。所以异步并非多线程,单线程同样可以异步。上面的例子同样可以改成await的形式。
1 | // example2_3_2 |
上面这个例子所有调用全部在主线程中完成,并且使用了await,因此await并不会开启多线程,await具体用没用多线程完全取决与具体的实现
以下是我个人理解与笔记
程序很好理解,主要是更正了我await就是开启一个多线程这个错误的认识
3.2 强大的MongoBson库
GitHub原地址:
黑体字为作者(熊猫大佬)原创,红色为个人理解
后端开发,统计了一下大概有这些场景需要用到序列化:
- 对象通过序列化反序列化clone
- 服务端数据库存储数据,二进制
- 分布式服务端,多进程间的消息,二进制
- 后端日志,文本格式
- 服务端的各种配置文件,文本格式 C#序列化库有非常非常多了,protobuf,json等等。但是这些序列化库都无法应当所有场景,既要可读又要小。protobuf不支持复杂的对象结构(无法使用继承),做消息合适,做数据库存储和日志格式并不好用。json做日志格式合适,但是做网络消息和数据存储就太大。我们当然希望一个库能满足上面所有场景,理由如下:
- 你想想某天你的配置文件需要放到数据库中保存,你不需要进行格式转换,后端直接把前端发过来的配置消息保存到数据库中,这是不是能减少非常多错误呢?
- 某天有些服务端的配置文件不用文件格式了,需要放在数据库中,同样,只需要几行代码就可以完成迁移。
- 某天后端服务器crash,你需要扫描日志进行数据恢复,把日志进行反序列化成C#对象,一条条进行处理,再转成对象保存到数据库就完成了。
- 对象保存在数据库,直接就可以看到文本内容,可以做各种类sql的操作
- 想像一个场景,一个配置文本对象,反序列化到内存,通过网络消息发送,存储到数据库中。整个过程一气呵成。 简单来说就是减少各种数据转换,减少代码,提高开发效率,提高可维护性。当然,Mongo Bson就能够满足。MongoDB库既可以序列化成文本也可以序列化成BSON的二进制格式,并且MongoDB本身就是一个游戏中使用非常多的数据库。Mongo Bson非常完善,是我见过功能最全使用最强大的序列化库,有些功能十分贴心。其支持功能如下:
- 支持复杂的继承结构
- 支持忽略某些字段序列化
- 支持字段默认值
- 结构多出多余的字段照样可以反序列化,这对多版本协议非常有用
- 支持ISupportInitialize接口使用,这个在反序列化的时候简直就是神器
- 支持文本json和二进制bson序列化
- MongoDB数据库支持 简单的介绍下mongo bson库
1.支持序列化反序列化成json或者bson
1 | public sealed class Player |
注意mongo的json跟标准的json有点区别,如果想用标准的json,可以传入一个JsonWriterSettings对象,限制使用JsonOutputMode.Strict模式
1 | // 使用标准json |
反序列化json:
1 | // 反序列化json |
反序列化bson:
1 | // 反序列化bson |
2.可以忽略某些字段
[BsonIgnore]该标签用来禁止字段序列化。
1 | public sealed class Player |
3.支持默认值以及取别名
[BsonElement] 字段加上该标签,即使是private字段也会序列化(默认只序列化public字段),该标签还可以带一个string参数,给字段序列化指定别名。
1 | public sealed class Player |
4.升级版本支持
[BsonIgnoreExtraElements] 该标签用在class上面,反序列化时用来忽略多余的字段,一般版本兼容需要考虑,低版本的协议需要能够反 序列化高版本的内容,否则新版本加了字段,旧版本结构反序列化会出错
1 | [] |
5.支持复杂的继承结构
mongo bson库强大的地方在于完全支持序列化反序列化继承结构。需要注意的是,继承反序列化需要注册所有的父类,有两种方法: a. 你可以在父类上面使用[BsonKnownTypes]标签声明继承的子类,这样mongo会自动注册,例如:
1 | [] |
这样有缺陷,因为框架并不知道一个类会有哪些子类,这样做对框架代码有侵入性,我们希望能解除这个耦合 。可以扫描程序集中所有子类父类的类型,将他们注册到mongo驱动中
1 | Type[] types = typeof(Game).Assembly.GetTypes(); |
这样完全的自动化注册,使用者也不需要关系类是否注册。
6.ISupportInitialize接口
mongo bson反序列化时支持一个ISupportInitialize接口,ISupportInitialize有两个方法
1 | public interface ISupportInitialize |
BeginInit在反序列化前调用,EndInit在反序列化后调用。这个接口非常有用了,可以在反序列化后执行一些操作。例如
1 | [] |
InnerConfig是ET中进程内网地址的配置,由于IPEndPoint不太好配置,我们可以配置成string形式,然后反序列化的时候在EndInit中把string转换成IPEndPoint。 同样我给protobuf反序列化方法也加上了这个调用,参考ProtobufHelper.cs,ET的protobuf因为要支持ilruntime,所以去掉了map的支持,假如我们想要一个map怎么办呢?这里我给生成的代码都做了手脚,把proto消息都改成了partial class,这样我们可以自己扩展这个class,比如:
1 | message UnitInfo |
这个网络消息有个repeated UnitInfo字段,在protobuf中其实是个数组,使用起来不是很方便,我希望转成一个Dictionary<Int64, UnitInfo>的字段,我们可以做这样的操作:
1 | public partial class G2C_EnterMap: ISupportInitialize |
通过这样一段代码把消息进行扩展一下,反序列化出来之后,自动转成了一个Dictionary。
以下是我个人理解与笔记
被猫大狠狠安利了一波Bson,这种一条龙服务确实舒服。。。值得学习
3.3 一切皆组件
GitHub原文地址:
黑体字为作者(熊猫大佬)原创,红色为个人理解
目前十分流行ECS设计,主要是守望先锋的成功,引爆了这种技术。守望先锋采用了状态帧这种网络技术,客户端会进行预测,预测不准需要进行回滚,由于组件式的设计,回滚可以只回滚某些组件即可。ECS最重要的设计是逻辑跟数据的完全分离。即EC是纯数据,System实际上就是逻辑,由数据驱动逻辑。数据驱动逻辑是什么意思呢?很简单通过Update检测数据变化,通过事件机制来订阅数据变化,这就是所谓的数据驱动了。其它的特点例如缓存命中,在编写逻辑上来说并不太重要,现代游戏都用脚本,连脚本的性能都能容忍怎么会在乎缓存命中那点性能提升?ET在设计的时候吸收了这些想法,但是并不完全照搬,目前的设计是我经过长期的思考跟重构得来的,还是有些自己特色。
传统的ECS写逻辑作者看来存在不少缺陷,比如为了复用,数据必然要拆成非常小的颗粒,会导致组件非常非常多。但是游戏是多人合作开发的,每个人基本上只熟悉自己的模块,最后可能造成组件大量冗余。还有个问题,常见的ECS是扁平式的,Entity跟Component只有一层。组件一多,开发功能可能不知道该使用哪些Component。好比一家公司,最大的是老板,老板手下带几百个人,老板不可能认识所有的人,完成一项任务,老板没法挑出自己需要的人。合理的做法是老板手下应该有几个经理,每个经理手下应该有几个主管,每个主管管理几个工人,这样形成树状的管理结构才会容易管理。这类似ET的做法,Entity可以管理Component,Component管理Entity,甚至Component还可以挂载Component。例如:人由头,身体,手,脚组成,而头又由眼睛,耳朵,鼻子,嘴巴组成。
1 | Head head = human.AddComponent<Head>(); |
ET中,所有数据都是Component,包括Entity,Entity继承于ComponentWithId,ComponentWithId继承于Component,所以Entity本质上也是一个Component,只不过它可以挂载其它的Component。实际使用中你可以继承Component,ComponentWithId,Entity三者之一,区别是如果该类需要挂载组件则继承Entity,如果不需要挂载组件但是需要带个逻辑Id则继承ComponentWithId,剩下的继承Component。ET的Entity是可以有数据成员的,通用的数据放在Entity身上作为成员,不太通用的数据可以作为组件挂在Entity身上。比如物品的设计,所有物品都有配置id,数量,等级的字段,这些字段没有必要做成组件,放在Entity身上使用会更加方便。
1 | class Item: Entity |
ET的这种设计数据是一种树状的结构,非常有层次,能够非常轻松的理解整个游戏的架构。顶层Game.Scene,不同模块的数据都挂载在Game.Scene上面,每个模块自身下面又可以挂载很多数据。每开发一个新功能不用思考太多,类该怎么设计,数据放在什么地方,挂载这里会不会导致冗余等等。比如我玩家需要做一个道具系统,设计一个ItemsComponent挂在Player身上即可,需要技能开发一个SpellComponent挂在Player身上。全服需要做一个活动,搞个活动组件挂在Game.Scene上面。这种设计任务分派会很简单,十分的模块化。
组件的一些细节
1.组件的创建
组件的创建不要自己去new,应该统一使用ComponentFactory创建。ComponentFactory提供了三组方法用来创建组件Create,CreateWithParent,CreateWithId。Create是最简单的创建方式,它做了几个处理
a. 根据组件类型构造一个组件
b. 将组件加入事件系统,并且抛出一个AwakeSystem
c. 是否启用对象池
CreateWithParent在Create的基础上提供了一个Parent对象,设置到Component.Parent字段上。CreateWithId是用来创建ComponentWithId或者其子类的,在Create的基础上可以自己设置一个Id, Component在创建的时候可以选择是否使用对象池。三类工厂方法都带有一个fromPool的参数,默认是true。
2.组件的释放
Component都继承了一个IDisposable接口,需要注意,Component有非托管资源,删除一个Component必须调用该接口。该接口做了如下的操作
a. 抛出Destroy System
b. 如果组件是使用对象池创建的,那么在这里会放回对象池
c. 从全局事件系统(EventSystem)中删除该组件,并且将InstanceId设为0
如果组件挂载Entity身上,那么Entity调用Dispose的时候会自动调用身上所有Component的Dispose方法。
3.InstanceId的作用
任何Component都带有一个InstanceId字段,这个字段会在组件构造,或者组件从对象池取出的时候重新设置,这个InstanceId标识这个组件的身份。为什么需要这么一个字段呢?有以下几个原因
- 对象池的存在,组件未必会释放,而是回到对象池中。在异步调用中,很可能这个组件已经被释放了,然后又被重新利用了起来,这样我们需要一种方式能区分之前的组件对象是否已经被释放,例如下面这段代码:
1 | public static async ETVoid UpdateAsync(this ActorLocationSender self) |
**while (true)中是段异步方法,await self.GetAsync()之后很可能ActorLocationSender对象已经被释放了,甚至有可能这个对象又被其它逻辑从对象池中再次利用了起来。我们这时候可以通过InstanceId的变化来判断这个对象是否已经被释放掉。
- InstanceId是全局唯一的,并且带有位置信息,可以通过InstanceId来找到对象的位置,将消息发给对象。这个设计将会Actor消息中利用到。这里暂时就不讲了。**
以下是我个人理解与笔记
我在这里主要写一下我对创建组件的感悟吧
举个例子吧
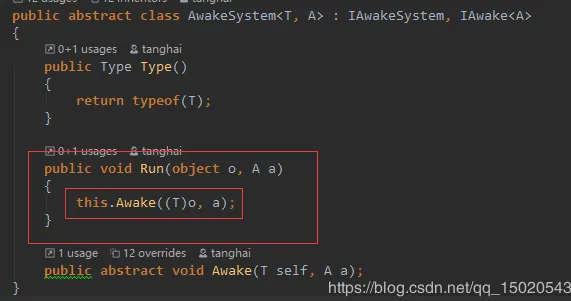
我们先跟进AddComponent
我们先看K这个泛型约束,它意为K一定是一个new出来的Component类(子类),而P1则由编译器自己根据后面传入的p1参数自己判定类型
然后是红框里面CreateWithParent
然后是第三个红框里面的Awake
最后我们查看最后一行的那个Awake实现
至此,添加组件——拿到组件实例——执行组件的Awake流程完整结束,其余的生命周期函数如Update和Start等都大致相同
上图是所有的生命周期系统,可以在EventSystem里面查看更多详情,比如Update大致就是EventSystem的Update函数轮询驱动所有包含UpdateSystem的Component
猫大的代码写的非常好,很容易懂,请大家自己多思考
3.4 事件机制EventSystem
GitHub原文地址:
黑体字为作者(熊猫大佬)原创,红色为个人理解
ECS最重要的特性一是数据跟逻辑分离,二是数据驱动逻辑。什么是数据驱动逻辑呢?不太好理解,我们举个例子 一个moba游戏,英雄都有血条,血条会在人物头上显示,也会在左上方头像UI上显示。这时候服务端发来一个扣血消息。我们怎么处理这个消息?第一种方法,在消息处理函数中修改英雄的血数值,修改头像上血条显示,同时修改头像UI的血条。这种方式很明显造成了模块间的耦合。第二种方法,扣血消息处理函数中只是改变血值,血值的改变抛出一个hpchange的事件,人物头像模块跟UI模块都订阅血值改变事件,在订阅的方法中分别处理自己的逻辑,这样各个模块负责自己的逻辑,没有耦合。 ET提供了多种事件,事件都是可以多次订阅的:
- AwakeSystem,组件工厂创建组件后抛出,只抛出一次,可以带参数
1 | Player player = ComponentFactory.Create<Player>(); |
- StartSystem,组件UpdateSystem调用前抛出
1 | // 订阅Player的Start事件 |
- UpdateSystem,组件每帧抛出
1 | // 订阅Player的Update事件 |
- DestroySystem,组件删除时抛出
1 | // 订阅Player的Destroy事件 |
- ChangeSystem,组件内容改变时抛出,需要开发者手动触发
1 | // 订阅Player的Destroy事件 |
- DeserializeSystem,组件反序列化之后抛出
1 | // 订阅Player的Deserialize事件 |
- LoadSystem,EventSystem加载dll时抛出,用于服务端热更新,重新加载dll做一些处理,比如重新注册handler
1 | // 订阅Player的Load事件 |
- 普通的Event,由开发者自己抛出,可以最多带三个参数。另外客户端热更层也可以订阅mono层的Event事件
1 | int oldhp = 10; |
- 除此之外还有很多事件,例如消息事件。消息事件使用MessageHandler来声明,可以带参数指定哪种服务器需要订阅。
1 | [] |
**更具体的消息事件等到讲消息的时候再细细讲解了
- 数值事件,数值模块再讲解
…, 更多的事件由自己去开发。**
ET框架的逻辑就是由以上各种事件来驱动的。
以下是我个人理解与笔记
我发现可以把我上篇的笔记拿一部分过来直接用,所以麻烦大家自己移步看一下
https://blog.csdn.net/qq_15020543/article/details/88201571
这一篇,猫大更加详细的介绍了ET的事件系统,想必已经有厉害的同学预见到ET框架的可拓展以及方便性了
最赞的是,直接用属性字段来订阅事件这操作实在太帅了啊啊啊啊啊啊啊啊啊啊啊啊
5.4 Actor模型
GitHub原文地址:
黑体字为作者(熊猫大佬)原创,红色为个人理解
Actor介绍
在讨论Actor模型之前先要讨论下ET的架构,游戏服务器为了利用多核一般有两种架构,单线程多进程跟单进程多线程架构。两种架构本质上其实区别不大,因为游戏逻辑开发都需要用单线程,即使是单进程多线程架构,也要用一定的方法保证单线程开发逻辑。ET采用的是单线程多进程的架构,而传统Actor模型一般是单进程多线程的架构,这点是比较大的区别,不能说谁更好,只能说各有优势。优劣如下:
- 逻辑需要单线程这点都是一样的,erlang进程逻辑是单线程的,skynet lua虚拟机也是单线程的。ET中一个进程其实相当于一个erlang进程,一个skynet lua虚拟机。
- 采用单线程多进程不需要自己再写一套profiler工具,可以利用很多现成的profiler工具,例如查看内存,cpu占用直接用top命令,这点erlang跟skynet都需要自己另外搞一套工具。
- 多进程单线程架构还有个好处,单台物理机跟多台物理机是没有区别的,单进程多线程还需要考虑多台物理机的处理。
- 多进程单线程架构一点缺陷是消息跨进程需要进行序列化反序列化,占用一点资源。另外发送网络消息会有几毫秒延时。一般这些影响可以忽略。 最开始Actor模型是给单进程多线程架构使用的,这是有原因的,因为多线程架构开发者很容易随意的访问共享变量,比方说一个变量a, 线程1能访问,线程2也能访问,这样两个线程在访问变量a的时候都需要加锁,共享变量多了之后锁到处都是,会变得无法维护,框架肯定不能出现到处是线程共享变量的情况。为了保证多线程架构不出问题,必须提供一种开发模型保证多线程开发简单又安全。erlang语言的并发机制就是actor模型。erlang虚拟机使用多线程来利用多核。erlang设计了一种机制,它在虚拟机之上设计了自己的进程。最简单的,每个erlang进程都管理自己的变量,每个erlang进程的逻辑都跑在一个线程上,erlang进程跟进程之间逻辑完全隔离,这样就不存在两个线程访问同一变量的情况了也就不存在多线程竞争的问题。接下来问题又出现了,既然每个erlang进程都有自己的数据,逻辑完全是隔离的,两个erlang进程之间应该怎么进行通信呢?这时Actor模型就登场了。erlang设计了一种消息机制:一个进程可以向其它进程发送消息,erlang进程之间通过消息来进行通信,看到这会不会感觉很熟悉?这不就是操作系统进程间通信用的消息队列吗?没错,其实是类似的。erlang里面拿到进程的id就能给这个进程发送消息。
如果消息只发给进程其实还是有点不方便。比如拿一个erlang进程做moba战队进程,战斗进程中有10个玩家,如果使用erlang的actor消息,消息只能发送给战斗进程,但是很多时候消息是需要发送给一个玩家的,这时erlang需要根据消息中的玩家Id,把消息再次分发给具体的玩家,这样其实多绕了一圈。
ET的Actor
ET根据自己架构得特点,没有完全照搬erlang的Actor模型,而是提供了Entity对象级别的Actor模型。这点跟erlang甚至传统的Actor机制不一样。ET中,Actor是Entity对象,Entity挂上一个MailboxComponent组件就是一个Actor了。只需要知道Entity的InstanceId就可以发消息给这个Entity了。其实erlang的Actor模型不过是ET中的一种特例,比如给ET服务端Game.Scene当做一个Actor,这样就可以变成进程级别的Actor。Actor本质就是一种消息机制,这种消息机制不用关心位置,只需要知道对方的InstanceId(ET)或者进程的Pid(erlang)就能发给对方。
1 | 语言 | ET | Erlang | Skynet |
ET的Actor的使用
普通的Actor,我们可以参照Gate Session。map中一个Unit,Unit身上保存了这个玩家对应的gate session。这样,map中的消息如果需要发给客户端,只需要把消息发送给gate session,gate session在收到消息的时候转发给客户端即可。map进程发送消息给gate session就是典型的actor模型。它不需要知道gate session的位置,只需要知道它的InstanceId即可。MessageHelper.cs中,通过GateSessionActorId获取一个ActorMessageSender,然后发送。
1 | // 从Game.Scene上获取ActorSenderComponent,然后通过InstanceId获取ActorMessageSender |
问题是map中怎么才能知道gate session的InstanceId呢?这就是你需要想方设法传过去了,比如ET中,玩家在登录gate的时候,gate session挂上一个信箱MailBoxComponent,C2G_LoginGateHandler.cs中
1 | session.AddComponent<MailBoxComponent, string>(MailboxType.GateSession); |
玩家登录map进程的时候会把这个gate session的InstanceId带进map中去,C2G_EnterMapHandler.cs中
1 | M2G_CreateUnit createUnit = (M2G_CreateUnit)await mapSession.Call(new G2M_CreateUnit() { PlayerId = player.Id, GateSessionId = session.InstanceId }); |
Actor消息的处理
首先,消息到达MailboxComponent,MailboxComponent是有类型的,不同的类型邮箱可以做不同的处理。目前有两种邮箱类型GateSession跟MessageDispatcher。GateSession邮箱在收到消息的时候会立即转发给客户端,MessageDispatcher类型会再次对Actor消息进行分发到具体的Handler处理,默认的MailboxComponent类型是MessageDispatcher。自定义一个邮箱类型也很简单,继承IMailboxHandler接口,加上MailboxHandler标签即可。那么为什么需要加这么个功能呢,在其它的actor模型中是不存在这个特点的,一般是收到消息就进行分发处理了。原因是GateSession的设计,并不需要进行分发处理,因此我在这里加上了邮箱类型这种设计。MessageDispatcher的处理方式有两种一种是处理对方Send过来的消息,一种是rpc消息
1 | // 处理Send的消息, 需要继承AMActorHandler抽象类,抽象类第一个泛型参数是Actor的类型,第二个参数是消息的类型 |
1 |
|
我们需要注意一下,Actor消息有死锁的可能,比如A call消息给B,B call给C,C call给A。因为MailboxComponent本质上是一个消息队列,它开启了一个协程会一个一个消息处理,返回ETTask表示这个消息处理类会阻塞MailboxComponent队列的其它消息。所以如果出现死锁,我们就不希望某个消息处理阻塞掉MailboxComponent其它消息的处理,我们可以在消息处理类里面新开一个协程来处理就行了。例如:
1 | [] |
相关资料可以谷歌一下Actor死锁的问题。
下面是个人笔记
我们可以感受到,Actor机制实质上就是一种消息的托管机制,类似我们经常用到的事件订阅与分发,我们只要把包含完整数据的消息发出去,不用管谁会接收消息,我们的代码根据ID找到相应的接受者。
5.5 Actor Location
GitHub原文地址:
黑体字为作者(熊猫大佬)原创,红色为个人理解
Actor Location
Actor模型只需要知道对方的InstanceId就能发送消息,十分方便,但是有时候我们可能无法知道对方的InstanceId,或者是一个Actor的InstanceId会发生变化。这种场景很常见,比如:很多游戏是分线的,一个玩家可能从1线换到2线,还有的游戏是分场景的,一个场景一个进程,玩家从场景1进入到场景2。因为做了进程迁移,玩家对象的InstanceId也就变化了。ET提供了给这类对象发送消息的机制,叫做Actor Location机制。其原理比较简单:
- 因为InstanceId是变化的,对象的Entity.Id是不变的,所以我们首先可以想到使用Entity.Id来发送actor消息
- 提供一个位置进程(Location Server),Actor对象可以将自己的Entity.Id跟InstanceId作为kv存到位置进程中。发送Actor消息前先去位置进程查询到Actor对象的InstanceId再发送actor消息。
- Actor对象在一个进程创建时或者迁移到一个新的进程时,都需要把自己的Id跟InstanceId注册到Location Server上去
- 因为Actor对象是可以迁移的,消息发过去有可能Actor已经迁移到其它进程上去了,所以发送Actor Location消息需要提供一种可靠机制
- ActorLocationSender提供两种方法,Send跟Call,Send一个消息也需要接受者返回一个消息,只有收到返回消息才会发送下一个消息。
- Actor对象如果迁移走了,这时会返回Actor不存在的错误,发送者收到这个错误会等待1秒,然后重新去获取Actor的InstanceId,然后重新发送,目前会尝试5次,5次过后,抛出异常,报告错误
- ActorLocationSender发送消息不会每次都去查询Location Server,因为对象迁移毕竟比较少见,只有第一次去查询,之后缓存InstanceId,以后发送失败再重新查询。
- Actor对象在迁移过程中,有可能其它进程发送过来消息,这时会发生错误,所以location server提供了一种Lock的机制。对象在传送前,删掉在本进程的信息,然后在location server上加上锁,一旦锁上后,其它的对该key的请求会进行队列。
- 传送前因为对方删除了本进程的actor,所以其它进程会发送失败,这时候他们会进行重试。重试的时候会重新请求location server,这时候会发现被锁了,于是一直等待
- 传送完成后,要unlock location server上的锁,并且更新新的地址,然后响应其它的location请求。其它发给这个actor的请求继续进行下去。 注意,Actor模型是纯粹的服务端消息通信机制,跟客户端是没什么关系的,很多用ET的新人看到ET客户端消息也有Actor接口,以为这是客户端跟服务端通信的机制,其实不是的。ET客户端使用这个Actor完全是因为Gate需要对客户端消息进行转发,我们可以正好利用服务端actor模型来进行转发,所以客户端有些消息也是继承了actor的接口。假如我们客户端不使用actor接口会怎么样呢?比如,Frame_ClickMap这个消息
1 | message Frame_ClickMap // IActorLocationMessage |
我们可能就不需要ActorId这个字段,消息发送到Gate,gate看到是Frame_ClickMap消息,它需要转发给Map上的Unit,转发还好办,gate可以从session中获取对应的map的unit的位置,然后转发,问题来了,Frame_ClickMap消息到了map,map怎么知道消息需要给哪个对象呢?这时候有几种设计:
- 在转发的底层协议中带上unit的Id,需要比较复杂的底层协议支持。
- 用一个消息对Frame_ClickMap消息包装一下,包装的消息带上Unit的Id,用消息包装意味着更大的消耗,增加GC。 个人感觉这两种都很差,不好用,而且就算分发给unit对象处理了,怎么解决消息重入的问题呢?unit对象仍然需要挂上一个消息处理队列,然后收到消息扔到队列里面。这不跟actor模型重复了吗?目前ET在客户端发给unit的消息做了个设计,消息做成actor消息,gate收到发现是actor消息,直接发到对应的actor上,解决的可以说很漂亮。其实客户端仍然是使用session.send跟call发送消息,发送的时候也不知道消息是actor消息,只有到了gate,gate才进行了判断,参考OuterMessageDispatcher.cs
Actor Location消息的处理
ActorLocation消息发送
1 | // 从Game.Scene上获取ActorLocationSenderComponent,然后通过Entity.Id获取ActorLocationSender |
ActorLocation消息的处理跟Actor消息几乎一样,不同的是继承的两个抽象类不同,注意actorlocation的抽象类多了个Location
1 | // 处理send过来的消息, 需要继承AMActorLocationHandler抽象类,抽象类第一个泛型参数是Actor的类型,第二个参数是消息的类型 |
1 | // 处理Rpc消息, 需要继承AMActorRpcHandler抽象类,抽象类第一个泛型参数是Actor的类型,第二个参数是消息的类型,第三个参数是返回消息的类型 |
1 |
ET的actor跟actor location的比喻
中国有很多城市(进程),城市中有很多人(entity对象)居住,每个人都有身份证号码(Entity.Id)。一个人每到一个市都需要办理居住证,分配到唯一的居住证号码(InstanceId),居住证号码的格式是2个字节市编号+4个字节时间+2个字节递增。身份证号码是永远不会变化的,但是居住证号码每到一个城市都变化的。 现在有个中国邮政(actor)。假设小明要发信给女朋友小红
- 小红为了收信,自己必须挂载一个邮箱(MailboxComponent),小红收到消息就会处理。注意这里处理是一个个进行处理的。有可能小红会同时收到很多人的信。但是她必须一封一封的信看,比方说小明跟小宝都发了信给小红,小红先收到小明的信,再收到了小宝的信。小红先读小明的信,小明信中让小红给外婆打个电话(产生协程)再给自己回信,注意这期间小红也不能读下一封信,必须打完电话后才能读小宝的信。当然小红自己可以选择不处理完成就开始读小宝的信,做法是小红开一个新的协程来处理小明的信。
- 假设小明知道小红的居住证号码,那么邮政(actor)可以根据居住证号码头两位找到小红居住的城市(进程),然后再根据小红的居住证编号,找到小红,把消息投递到小红的邮箱(MailboxComponent)中。这种是最简单的原生的actor模型
- ET还支持了一套actor location机制。假设小明不知道小红的居住证号码,但是他知道小红的身份证号码,怎么办呢?邮政开发了一套高级邮政(actor location)想了一个办法,如果一个人经常搬家,它还想收到信,那他到一个新的城市都必须把自己的居住证跟身份证上报到中央政府(location server),这样高级邮政能够通过身份证号码来发送邮件。方法就是去中央政府拿到小红的居住证号码,再利用actor机制发送。
- 假设小红之前在广州市,小明用小红的身份证给小红发信件了。 高级邮政获取了小红的居住证号码,给小红发信。发信的这个过程中,小红搬家了,从广州搬到了深圳,这时小红在中央政府上报了自己新的居住证。 高级邮政的信送到到广州的时候发现,小红不在广州。那么高级邮政会再次去中央政府获取小红的居住证,重新发送,有可能成功有可能再次失败,这个过程会重复几次,如果一直不成功则告诉小明,信件发送失败了。
- 高级邮政发信比较贵,而且人搬家的次数并不多,一般小明用高级邮政发信后会记住小红的居住证,下次再发的时候直接用居住证发信,发送失败了再使用高级邮政发信。
- 高级邮政的信都是有回执的,有两种回执,一种回执没有内容,只表示小红收到了信,一种回执带了小红的回信。小明在发信的时候可以选择使用哪种回执形式。小明给小红不能同时发送两封信,必须等小红的回执到了,小明才能继续发信。
下面是个人笔记
Actor Location可以认为是Actor的另一个版本,但本质一样,都是利用了中间者转发与定位消息
5.6 数值组件设计
GitHub原文地址:
数值组件设计
黑体字为作者(熊猫大佬)原创,红色为个人理解
类似魔兽世界,moba这种技能极其复杂,灵活性要求极高的技能系统,必须需要一套及其灵活的数值结构来搭配。数值结构设计好了,实现技能系统就会非常简单,否则就是一场灾难。比如魔兽世界,一个人物的数值属性非常之多,移动速度,力量,怒气,能量,集中值,魔法值,血量,最大血量,物理攻击,物理防御,法术攻击,法术防御,等等多达几十种之多。属性跟属性之间又相互影响,buff又会给属性增加绝对值,增加百分比,或者某种buff又会在算完所有的增加值之后再来给你翻个倍。
普通的做法:
一般就是写个数值类:
1 | class Numeric |
仔细一想,我一个盗贼使用的是能量,为什么要有一个Mp的值?我一个法师使用的是魔法为什么要有能量的字段?纠结这个搞毛,当作没看见不就行了吗?实在不行,我来个继承?
1 | // 法师数值 |
10个种族,每个种族7,8种英雄,光这些数值类继承关系,你就得懵逼了吧。面向对象是难以适应这种灵活的复杂的需求的。
再来看看Numeric类,每种数值可不能只设计一个字段,比如说,我有个buff会增加10点Speed,还有种buff增加50%的speed,那我至少还得加三个二级属性字段
1 | class Numeric |
SpeedAdd跟SpeedPct改变后,进行一次计算,就可以算出最终的速度值。buff只需要去修改SpeedAdd跟SpeedPct就行了。
1 | Speed = (SpeedInit + SpeedAdd) * (100 + SpeedPct) / 100 |
每种属性都可能有好几种间接影响值,可以想想这个类是多么庞大,初略估计得有100多个字段。麻烦的是计算公式基本一样,但是就是无法统一成一个函数,例如MaxHp,也有buff影响
1 | class Numeric |
也得写个Hp的计算公式
1 | MaxHp=(MaxHpInit + MaxHpAdd) * (100 + MaxHpPct) / 100 |
几十种属性,就要写几十遍,并且每个二级属性改变都要正确调用对应的公式计算. 非常麻烦! 这样设计还有个很大的问题,buff配置表填对应的属性字段不是很好填,例如疾跑buff(增加速度50%),在buff表中怎么配置才能让程序简单的找到并操作SpeedPct字段呢?不好搞。
ET框架采用了Key Value形式保存数值属性
1 | using System.Collections.Generic; |
1.数值都用key value来保存,key是数值的类型,由NumericType来定义,value都是整数,float型也可以转成整数,例如乘以1000;key value保存属性会变得非常灵活,例如法师没有能量属性,那么初始化法师对象不加能量的key value就好了。盗贼没有法力值,没有法术伤害等等,初始化就不用加这些。
2.魔兽世界中,一个数值由5个值来影响,可以统一使用一条公式:
1 | final = (((base + add) * (100 + pct) / 100) + finalAdd) * (100 + finalPct) / 100; |
比如说速度值speed,有个初始值speedbase,有个buff1增加10点绝对速度,那么buff1创建的时候会给speedadd加10,buff1删除的时候给speedadd减10,buff2增加20%的速度,那么buff2创建的时候给speedpct加20,buff2删除的时候给speedpct减20.甚至可能有buff3,会在最终值上再加100%,那么buff3将影响speedfinalpct。这5个值发生改变,统一使用Update函数就可以重新计算对应的属性了。buff配置中对应数值字段相当简单,buff配置中填上相应的NumericType,程序很轻松就能操作对应的数值。
3.属性的改变可以统一抛出事件给其它模块订阅,写一个属性变化监视器变得非常简单。例如成就模块需要开发一个成就生命值超过1000,会获得长寿大师的成就。那么开发成就模块的人将订阅HP的变化:
1 | /// 监视hp数值变化 |
同理,记录一次金币变化大于10000的异常日志等等都可以这样做。
有了这个数值组件,一个moba技能系统可以说已经完成了一半。
下面是个人笔记
先说几个注意点
- 枚举类型的值不是真正意义上的值,它是这个枚举所对应的ID,类似定义proto文件message{}体一样
- 数值组件和数值变化监听组件都要用到一个id,这个id是当前数值组件所在实体(Entity)的id
- 使用时需要给Game.Scene添加数值监听组件(NumericWatcherComponent:
一般是一个),并且给需要使用数值组件的实体(Entity:可以任意个)添加数值组件(NumericComponent
) - 对于直接的枚举类型的对比,都是比较ID的大小
- 之所以final要/10是因为确保改变的是自己想要的类型
- 不要直接对想取得的数值进行修改和赋值,不然无效 下面我用一个小例子来和大家一起学习吧
我们直接去客户端创建小骷髅的代码那里,M2C_CreateUnitsHandler
1 | using ETModel; |
这里为了做示例,修改了一下NumericComponent的Awake
1 | public void Awake() |
同样修改NumericWatcher_Hp_ShowUI
1 | namespace ETModel |
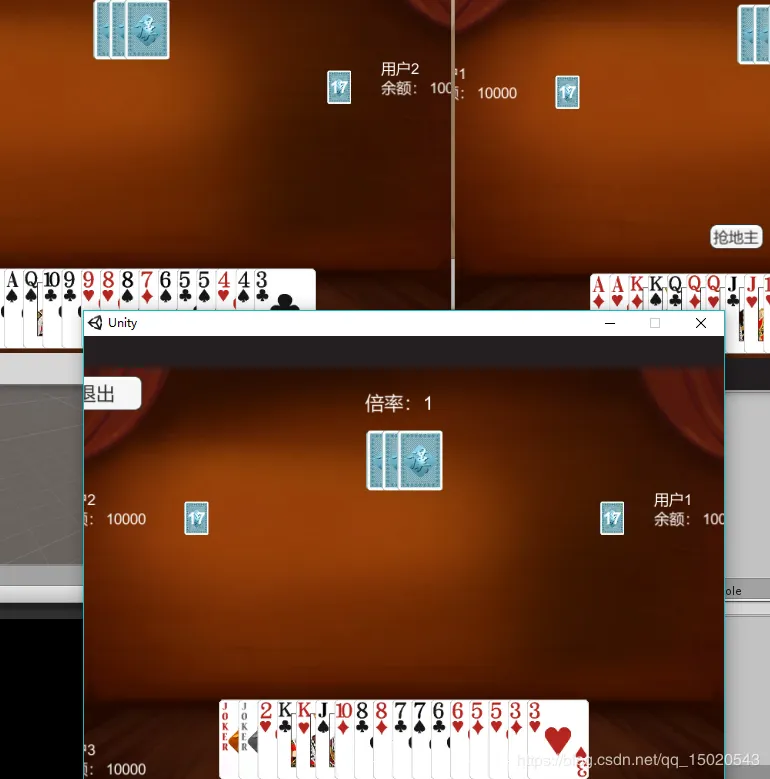
运行游戏
总结:一方面是理解了猫大的数值组件设计,另一方面,我们可以预见ET的组件化编程和异步语法将会极大方便与规范我们的开发,可以说,项目代码优美程度只取决于我们的想象力!
![微信]() 微信
微信![支付宝]() 支付宝
支付宝